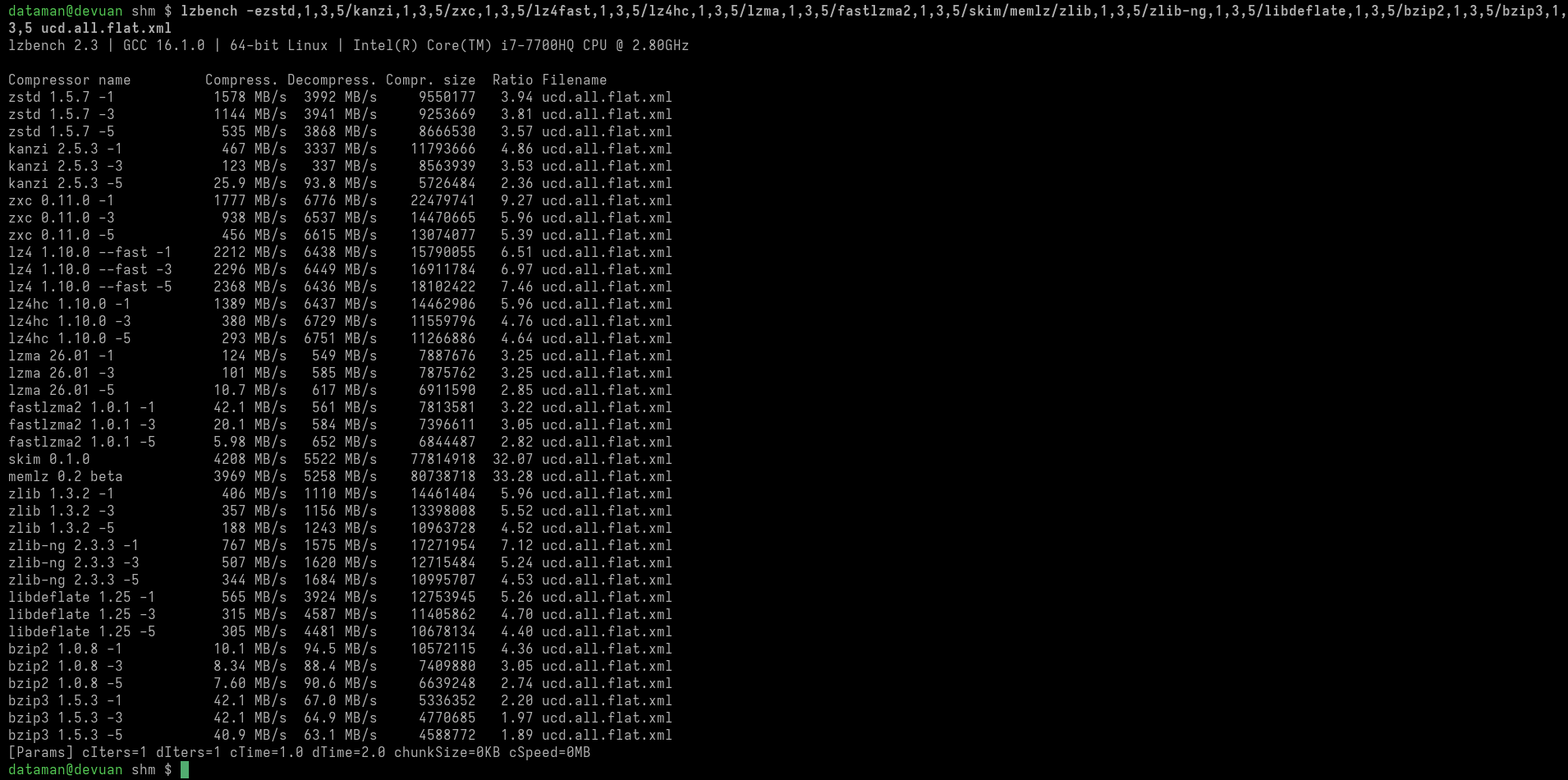
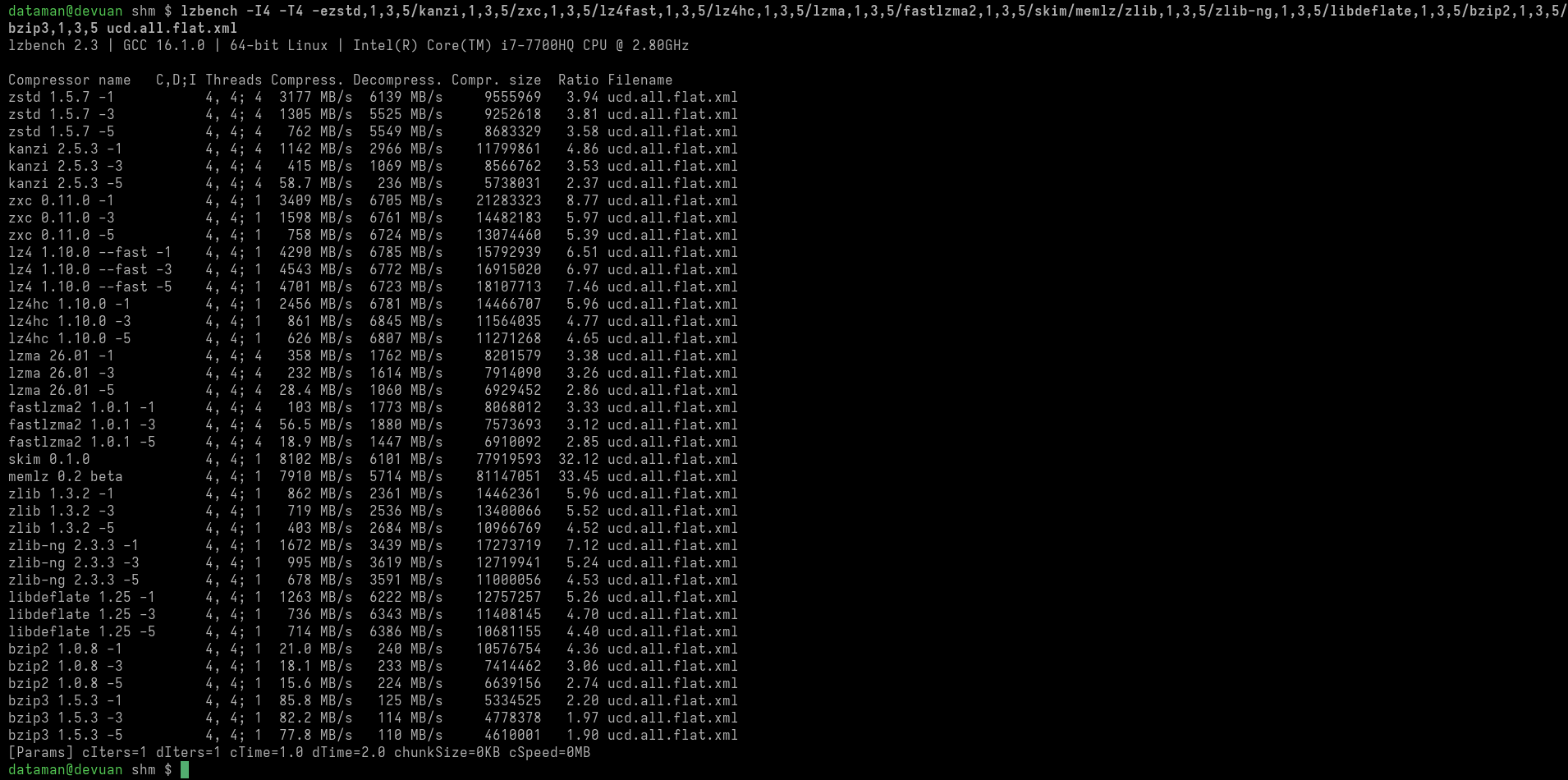
https://herbsutter.com/2026/06/13/brno-trip-report.
Несколько минут назад (прим.: 13 июня 2026 г.) комитет ISO по C++ завершил первое заседание по C++29 в прекрасном городе Брно, Чехия (в гибридном формате с онлайн-участием через Zoom).
Организатором этой встречи выступил Университет имени Менделя в Брно. Благодарим всех, кто принимал участие в её проведении, и в особенности Хану Дусикову, которая возглавила работу по подготовке мероприятия! Наши хозяева обеспечили нам высококачественные условия для проведения шестидневной встречи с понедельника по субботу.
В мероприятии приняли участие около 200 человек, из которых примерно 55% присутствовали на месте, а 45% — онлайн; они официально представляли 28 стран. На каждой встрече у нас регулярно появляются новые гости, которые никогда раньше не участвовали в мероприятии, и на этот раз, помимо новых участников, являющихся официальными представителями национальных организаций, было 25 новых гостей, в основном присутствовавших на месте. Ещё раз приветствуем всех!
В настоящее время в составе комитета действуют 22 подгруппы, 11 из которых в течение недели проводили заседания в рамках 6 параллельных сессий. Некоторые группы работали всю неделю, а другие — несколько дней или часть дня, в зависимости от объёма работы. Краткое изложение процедур ISO можно найти здесь.
Принято для C++29: Изменения и новые возможности ядра языка
Эти ссылки ведут на самые последние общедоступные версии каждой статьи. Если статья была доработана на заседании перед утверждением, ссылка отслеживает изменения и автоматически найдёт обновлённую версию, как только она будет загружена на общедоступный сайт.
Некоторые из принятых нововведений в языке и библиотеках уже сегодня поддерживаются в основных реализациях C++. «Принято для C++29» не означает, что «придётся ждать до 2029 года или позже, чтобы увидеть их поддержку в реальных компиляторах и стандартных библиотеках».
Помимо устранения ряда проблем, основная рабочая группа одобрила 19 документов, в том числе следующие:
-
P3596R3 «Неопределённое поведение и приложения IFNDR» (авторы: Joshua Berne, Timur Doumler, Jens Maurer и Shafik Yaghmour). Данная статья дополняет стандарт C++ двумя приложениями, в которых подробно каталогизированы и задокументированы все случаи неопределённого поведения (UB) в C++, включая случаи, помеченные как «некорректная форма, диагностика не требуется» (IFNDR). Данный каталог предназначен для содействия смягчению или устранению случаев UB, в том числе с помощью профилей.
Это была, простите за мой французский, целая «[метрическая] тонна» работы, проделанной на протяжении нескольких лет. Спасибо Shafik, Joshua, Timur, Jens и всем, кто помог им составить этот подробный каталог, благодаря чему теперь мы сможем систематически заняться этими случаями неопределённости (UB)!
Следующим шагом станет рассмотрение каждого случая в отдельности, которое начнётся в следующем месяце с целью систематического решения этих проблем к C++29, возможно, уже в течение следующего года (подробнее об этом ниже).
Здесь, в C++, мы смотрим в глаза реальности без страха и пристрастий. На случай, если это нужно повторить: «Да, Вирджиния, существует динамичный, живой и современный язык программирования под названием C++». (Только, в отличие от оригинала, эта версия — правда для взрослых).
-
P3097R3 «Контракты в C++: виртуальные функции» (авторы: Timur Doumler, Joshua Berne и Gašper Ažman). Цитата из статьи:
«Утверждения переопределяющей функции не зависят от утверждений в переопределяемой функции. При вызове виртуальной функции оцениваются утверждения о предварительных и конечных условиях как статически выбранной функции, так и конечной переопределяющей функции. Данный подход развивает ранее предложенные решения, поддерживая более широкий спектр сценариев использования, встречающихся в существующем коде, более естественно интегрируясь с семантикой оценки контрактов и обработкой нарушений контрактов в C++26, а также лучше подходя для языка C++, чем более ограничительные модели в таких языках, как Eiffel и D».
Добавление этой функции устраняет одну из основных претензий к контрактам в C++26, а именно то, что первоначальная версия контрактов не поддерживала виртуальные функции. Теперь, менее чем через три месяца после технического завершения работы над C++26, в проекте стандарта C++29 контракты уже поддерживают виртуальные функции. Это свидетельствует о том, что комитет серьёзно настроен на развитие контрактов C++26 в рамках C++29. Спасибо, Timur, Joshua and Gašper!
-
P3668R4 «Операции инкремента и декремента в постфиксной нотации по умолчанию» (авторы: Matthew Taylor и Alex). В данной статье добавляется поддержка =default для операторов инкремента и декремента в постфиксной нотации, что позволяет использовать каноническое определение, отсылающее к префиксным версиям, без необходимости вручную писать шаблонный код (и, возможно, допускать ошибки). Спасибо, Matthew и Alex! Например, приведённый в статье пример теперь допустим в проекте C++29:
class foo{
int member;
public:
constexpr foo& operator++(){
++member;
return *this;
}
constexpr foo operator++(int) = default;
};
struct A { int a; };
struct B : A { int b; };
B{{1}, 2} // уже допустимо в C++17
B{1, 2} // уже допустимо в C++17
B{.a=1, .b=2} // теперь допустимо в C++29
B{{.a=1}, .b=2} // теперь допустимо в C++29
B{.a{1}, .b{2}} // теперь допустимо в C++29
B{.b=2, .a=1} // остаётся недопустимым
Кроме того, мы добавили ещё целый ряд языковых расширений и улучшений.
Принято для C++29: Изменения и новые возможности стандартной библиотеки
Помимо устранения ряда проблем, в стандартную библиотеку были включены 18 статей, в том числе следующие:
- P3091 «Улучшенные операции поиска для map, unordered_map и flat_map» (автор: Pablo Halpern). Этот документ добавляет в C++29 поддержку вызова
.lookup(key) в стиле Python для map, unordered_map и flat_map. Эта функция, возвращающая опциональный параметр, открывает возможности, недоступные сегодня с помощью оператора [], который всегда вставляет элемент, если его нет, и find, который находит только те элементы, которые присутствуют. Спасибо, Pablo! Вот пример из статьи:
constexpr double inf = std::numeric_limits<double>::infinity();
double largest = -inf;
for (int i = 1; i <= 100; ++i) {
largest = std::max(largest, theMap.lookup(i).value_or(-inf));
}
- P3125R6 «Маркировка указателей constexpr» (автор: Hana Dusíková, известная как «королева
constexpr»). Представленный в этой статье тип указателя с тегом pointer_tag_pair<Pointer, BitsRequested = /* доступные младшие биты */, Tag = unsigned> обеспечивает переносимую поддержку хранения информации в младших битах указателей. Это библиотека низкого уровня, полезная для решения многих задач, включая обеспечение безопасности памяти и усиление защиты. Спасибо, Hana!
- P3248 «Сделать [u]intptr_t обязательными» (автор: Gonzalo Brito Gadeschi). Формально в C и C++ до сих пор типы
intptr_t и uintptr_t были «необязательными», поэтому реализация на C++ могла не поддерживать их. Поскольку они полезны для низкоуровневого кода и уже широко поддерживаются, теперь стандарт C++ будет требовать их наличия. Спасибо, Gonzalo!
Мы также добавили ряд других расширений и улучшений библиотеки.
Другие достижения, в частности в области обеспечения безопасности работы с памятью
На этой неделе мы также добились других важных успехов в работе над функциями, которые пока не готовы к включению в проект стандарта.
Приведённый ниже список не является исчерпывающим, но я хотел бы особо выделить прогресс, достигнутый в нескольких направлениях, связанных с безопасностью памяти:
- Систематическое решение проблемы неопределённого поведения (UB) в C++ для стандарта C++29. Подгруппа по развитию языка (EWG) также одобрила выделение значительного времени этим летом и осенью на построчное рассмотрение в режиме телеконференции документа P3100 «Концептуальная основа для систематического решения проблемы неопределённого поведения в стандарте C++» (авторы: Timur Doumler and Joshua Berne), с целью включения его в стандарт C++29. Отличное краткое изложение можно найти в аннотации к документу.
- Спецификация профилей для C++29. Подгруппа по безопасности и защите (SG23) приняла решение разработать спецификацию профилей, которая позволит использовать правила статического и иного анализа, ограничивающие набор функций C++, с целью обеспечения того, чтобы в коде не использовались нежелательные (например, небезопасные с точки зрения памяти) операции, и тем самым усилить безопасность кода C++ определёнными способами. Эта спецификация будет включена в C++29, если она будет готова вовремя, как ожидается; в противном случае она может быть опубликована в виде технического документа одновременно с C++29.
- Профиль инициализации. Группа SG23 также рассмотрела текущий проект документа P4222 «Профиль инициализации» (автор: Bjarne Stroustrup), и мы рассчитываем добиться дальнейшего прогресса в этой работе в течение этого года, в том числе с учётом опыта реализации по крайней мере в одной крупной кодовой базе компилятора.
Как я уже упоминал в своих предыдущих отчетах о поездках, среди других документов по профилям, над которыми я ранее работал, можно назвать P3984 «Профиль безопасности типов» (автор: Bjarne Stroustrup) и P3589R2 «Профили C++: инфраструктура» (автор: Gabriel Dos Reis), а также ряд других дополняющих их документов с предложениями по профилям.
Сказать, что это были бы чрезвычайно важные и исторические достижения — значит сильно преуменьшить их значение:
- предоставляется способ систематически решать проблемы, связанные с неопределённым поведением (UB) в C++, и
- предоставляется способ гарантировать, что программа на C++ обладает определёнными свойствами, например, отсутствие ошибок, связанных с безопасностью работы с памятью.
Мы ещё не достигли этой цели, но обе задачи теперь явно выходят за рамки простого желания; это серьёзные рабочие задачи, по которым комитет намерен добиться значительного прогресса в ближайшем будущем. Я буду продолжать освещать эти усилия в будущих отчётах о поездках по мере продвижения работы.
Напоминание для тех, кто по-прежнему скептически относится к тому, что реализация UB на C++ когда-нибудь станет возможной: помните, что мы уже этим занимаемся. Не живите прошлым… «Уже не 2021 год». BeCPP, YouTube.
- Код
constexpr C++, который в настоящее время охватывает практически весь язык C++ и стандартную библиотеку, уже гарантированно не вызывает неопределённого поведения при выполнении на этапе компиляции.
- В C++26 были устранены ещё два основных источника неопределённого поведения (UB): использование неинициализированных переменных стека больше не приводит к UB, а в упрочнённой стандартной библиотеке C++ добавлена защита от выхода за пределы для десятков наиболее распространённых операций с границами (эта функция уже широко внедрена для упрочнения платформ Apple и Google; подробнее об этом см. в моём предыдущем отчёте о поездке).
В заключение
Еще раз благодарим около 200 экспертов, которые приняли участие в заседании на этой неделе как очно, так и в режиме онлайн, а также всех тех, кто участвует в работе по стандартизации через свои национальные органы!
Но мы не собираемся сбавлять обороты… Мы продолжим проводить заседания подгрупп в Zoom, а наше следующее полное заседание состоится в ноябре в Армасан-дус-Бузиус, недалеко от Рио-де-Жанейро (Бразилия), где мы продолжим работу над добавлением новых возможностей в C++29. Надеюсь увидеть многих из вас там.
Спасибо всем, кто читает это сообщение, за ваш интерес и поддержку C++ и его стандартизации.