Странное, движки СУБД
Добрый день камрады. Недавно задумался о странном. Предположим - есть цель написать СУБД. И хочется чтобы она работала везде. В том числе на андроид. На чем такое писать? Pure C? C++? Java? Golang?
Добрый день камрады. Недавно задумался о странном. Предположим - есть цель написать СУБД. И хочется чтобы она работала везде. В том числе на андроид. На чем такое писать? Pure C? C++? Java? Golang?
Попалась мать в комплекте с 2630 v3.
Встанет ли на эту мать 2630L v4? :-)
И есть ли смысл в переплате?
L v3 я приобрел за 850 рублей, а L v4 стоит уже 4.500.
Еще вопрос: если я установлю Debian с обычной не-ECC памятью, а позже заменю ее на ECC, будет ли система дальше продолжать работать, или нужно будет сделать переустановку или что-то поменять?
Дано:
система ubuntu-20.04
железо: AMD FX(tm)-6300 Six-Core Processor,
M5A78L-M LE/USB3(bios - v5.02)
решил использовать этот комп для расчетов. Запустил 6 абсолютно одинаковых задачек моделирования чего-то. Разница только в начальном случайном числе.
вот, что показывает top:
Tasks: 239 total, 6 running, 233 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,0 us, 0,6 sy, 82,9 ni, 16,5 id, 0,1 wa, 0,0 hi, 0,0 si, 0,0 st
MiB Mem : 7680,0 total, 362,2 free, 5360,9 used, 1956,9 buff/cache
MiB Swap: 8192,0 total, 7838,0 free, 354,0 used. 1999,8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3928 xxx 30 10 1099912 363192 22576 R 100,0 4,6 1164:37 root.exe
3923 xxx 30 10 1662268 404528 3640 R 99,7 5,1 1163:23 root.exe
3924 xxx 30 10 1636572 458604 6800 R 99,7 5,8 1164:09 root.exe
3927 xxx 30 10 1138156 375096 3628 R 99,7 4,8 1163:01 root.exe
3925 xxx 30 10 14,2g 3,3g 6672 R 94,4 43,6 1163:07 root.exe
после 10ти часов счета отвалилась одна задача, как будто, ее убили kill’ом, и что-то стало происходить с распределением памяти для оставшихся процессов. Причем, подобное на этом компьютере случается не в первый раз.
На 3х других компах (2 Ryzen и AMD Phenom(tm) II X4) с абсолютно той же ОС такие фортели не наблюдаются задачи досчитываются с одинаковыми ресурсами используемой памяти до конца. Например, на AMD Phenom(tm):
top - 11:25:18 up 20:07, 1 user, load average: 4,03, 4,03, 4,00
Tasks: 209 total, 5 running, 204 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0,2 us, 1,2 sy, 98,5 ni, 0,0 id, 0,0 wa, 0,0 hi, 0,2 si, 0,0 st
MiB Mem : 7937,5 total, 924,3 free, 2208,4 used, 4804,8 buff/cache
MiB Swap: 8192,0 total, 8192,0 free, 0,0 used. 5428,3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3470 xxx 30 10 890304 399592 16428 R 99,7 4,9 1172:04 root.exe
3473 xxx 30 10 890600 393624 16664 R 99,7 4,8 1172:24 root.exe
3471 xxx 30 10 898620 436972 14196 R 98,7 5,4 1173:05 root.exe
3472 xxx 30 10 890064 393388 16756 R 98,3 4,8 1172:41 root.exe
Вопрос: это железо или софт?
P.S.dmesg кроме warning о ACPI (на который иностранный народ советует забить, если присутствуют lm-sensors, а они есть
Перемещено hobbit из general
Приветствую друзья! Подскажите, правильно ли мыслю в сторону NoSQL redis в следующей ситуации.
Есть база на mysql IP диапазона адресов:
A____________B________________BLOCK___
192.168.1.0___192.168.1.255___1_______
100.100.5.0___100.100.255.0___0_______
Некоторые диапазоны А-В сгруппированы по 3 и 4 октету и содержат более 255 адресов. Такой подход дал экономию в размере базы, но существенно увеличил время запроса.
Select выбирает ip в диапазоне от A до B. Столкнулись с тем, что частые выборки (в пике 15 запросов в секунду) тормозят сервер.
Начали присматриваться в сторону NoSQL redis без группировки адресов, планируется увеличить базу по объему, но значительно повысить скорость выборки.
Обновления в базе происходят регулярно, до 1000 update, delete в сутки.
Правильный ли подход в планировании задачи и поможет ли redis в увеличении количества select в данной ситуации?
Перемещено hobbit из general
Статья о создании процессов в Linux
( читать дальше... )
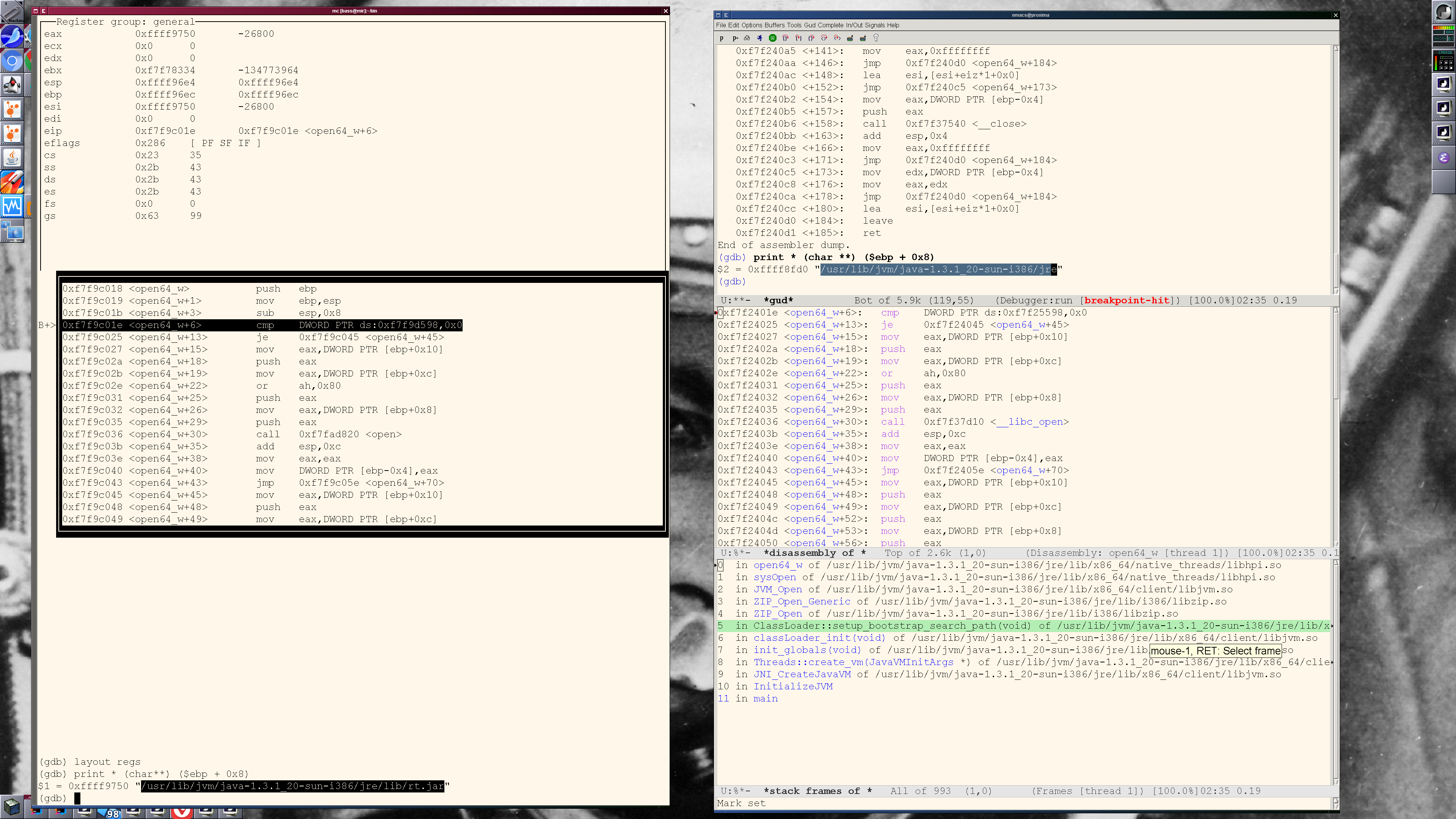
Всем здравствуйте.
На снимке – эксперименты, являющиеся продолжением вот этой темы.
Как уже не в первый раз убеждаюсь, утилита strace с ключом -k (печатать stack trace каждого вызова) – прекрасный инструмент для первичного (грубого) поиска проблемы. Собственно, именно таким способом было выяснено, что на Debian 9 и Debian 10+ поведение java начинает различаться, начиная с инструкции <open64_w+22> из libhpi.so. В результате последовательность
b main
r
b open64_w
cont
позволяет вплотную подобраться к проблеме, но уже пер-ректально «изнутри».
На снимке – сравнение консольного интерфейса GDB (слева) и Emacs (справа). Если честно, Emacs’ом для отладки пользовался в первый раз в жизни – и он мне понравился. Понравился даже больше, чем старик DDD (gnu.org), который умные люди используют для полноценной визуализации данных в памяти, но вот мне самому как-то не доводилось.
В чём ценность cgdb как обёртки над gdb, особенно в отсутствие исходного кода, – я так и не понял. Если у вас есть успешный успех опыт использования cgdb – поделитесь, пожалуйста. Аналогично, xxgdb, наверное, хорош – но для того, чтобы он завёлся в 2023 году, мне надо выкинуть из ~/.gdbinit буквально всё.
За каким рожном нужен убогий и деревянный как Буратино Nemiver, по недосмотру появившийся в пакетах Debian и заявляющий в качестве ключевых особенностей совместимость с GNOME 3 и умение скопировать значение переменной в буфер обмена (я не шучу: «Ability to copy the content of a variable into the GTK clipboard») – я тоже не понял. Зачем, если есть прекрасный Emacs?
В сухом остатке: насколько я понял, ebp + 0x8, ebp + 0xc и ebp + 0x10 – это адреса параметров функции. По первому адресу лежит строка, и строка эта на Debian 9 и Debian 10 разная:
/usr/lib/jvm/java-1.3.1_20-sun-i386/jre/lib/rt.jar (нормальное поведение, слева) и/usr/lib/jvm/java-1.3.1_20-sun-i386/jre (аномальное, справа).Стало быть, ерунда начинается ещё до системного вызова open()/openat() и происходит в одном из пяти вызовов:
sysOpen(...)JVM_Open(...)ZIP_Open_Generic(...)ZIP_Open(...)ClassLoader::setup_bootstrap_search_path(void)Будем копать дальше.
Вы привыкли что при втыкании наушников динамики отключаются? Сейчас отвыкать будем. Втыкаем наушники, запускаем hdajackretask, переназначаем наушники на тыловые каналы. Звуковое устройство меняется на 4.0, можно воспроизводить многоканал. Наушники на шее, динамики впереди, так и слушаем. Доброго вам слуха
Что ж, этот день настал. Будем делать gtk 2.26.
Минимальный план работ такой:
Приглашаются все желающие. Пишите ваши соображения.
Разные частичные наработки у меня есть, но я их пока нигде не публиковал. Причешу немного и выложу на гитхаб.
P.S. @hobbit, верни тэг gtk2 в БД сайта!!!
Привет.
Есть ли у кого пример/дока/статья на тему архитектуры десктопных GUI-приложений? Желательно с использованием Java и Swing/JavaFX тулкитов, но не обязательно, подойдут и другие стеки.
Интересует такой идиоматический пример как делать НОРМ.
Есть MVC, MVVM, MVP и т.д., т.п. Но... Их можно приготовить с разной степенью говености. А меня интересует хороший пример. Есть у кого-нибудь подобное на примете?
Не спрашивайте зачем, но было вот так
Было:
Диск /dev/sdc1: 596,17 GiB, 640132383744 байт, 1250258562 секторов
Единицы: секторов по 1 * 512 = 512 байт
Размер сектора (логический/физический): 512 байт / 512 байт
Размер I/O (минимальный/оптимальный): 512 байт / 512 байт
Тип метки диска: dos
Идентификатор диска: 0x2052474d
Устр-во Загрузочный начало Конец Секторы Размер Идентификатор Тип
/dev/sdc1p1 6579571 1924427647 1917848077 914,5G 70 DiskSecure Multi-Boot
/dev/sdc1p2 1953251627 3771827541 1818575915 867,2G 43 неизвестный
/dev/sdc1p3 225735265 225735274 10 5K 72 неизвестный
/dev/sdc1p4 2642411520 2642463409 51890 25,3M 0 Пустой
Элементы таблицы разделов упорядочены не так, как на диске.
# sudo fdisk /dev/sdc1
Добро пожаловать в fdisk (util-linux 2.36.1).
Изменения останутся только в памяти до тех пор, пока вы не решите записать их.
Будьте внимательны, используя команду write.
The device contains 'ntfs' signature and it will be removed by a write command. See fdisk(8) man page and --wipe option for more details.
Устройство не содержит стандартной таблицы разделов.
Создана новая метка DOS с идентификатором 0x34d946a3.
Команда (m для справки): x
Команды эксперта (m для справки): f
Nothing to do. Ordering is correct already.
Failed to fix partitions order.
Команды эксперта (m для справки): r
Команда (m для справки): w
Таблица разделов была изменена.
Синхронизируются диски.```
Стало вот так:
```# fdisk -l /dev/sdc1
Диск /dev/sdc1: 596,17 GiB, 640132383744 байт, 1250258562 секторов
Единицы: секторов по 1 * 512 = 512 байт
Размер сектора (логический/физический): 512 байт / 512 байт
Размер I/O (минимальный/оптимальный): 512 байт / 512 байт
Тип метки диска: dos
Идентификатор диска: 0x34d946a3
# fdisk -l
Устр-во Загрузочный начало Конец Секторы Размер Идентификатор Тип
/dev/sdc1 63 1250258624 1250258562 596,2G 7 HPFS/NTFS/exFAT
Диск /dev/sdc: 596,17 GiB, 640135028736 байт, 1250263728 секторов
Disk model: Transcend
Единицы: секторов по 1 * 512 = 512 байт
Размер сектора (логический/физический): 512 байт / 512 байт
Размер I/O (минимальный/оптимальный): 512 байт / 512 байт
Тип метки диска: dos
Идентификатор диска: 0x0c160c52
Устр-во Загрузочный начало Конец Секторы Размер Идентификатор Тип
/dev/sdc1 63 1250258624 1250258562 596,2G ``` 7 HPFS/NTFS/exFAT
Как получить доступ к данным на диске? Ничего пока не форматировал, но доступ к данным потерялСкоро (ближе к концу января) буду вводить в эксплуатацию сервер, хочу потестить производительность ZFS.
Цели:
Тестировать буду Intel P5800X (Optane) и Samsung PM1735 (TLC). Будет средний сервер на Xeon’e. Дистрибутив — Proxmox VE.
Принимаются пожелания (в виде указаний по настройке ZFS и конфигов/команд fio).
Предыдущее тестирование (2019 г.)
Тема в reddit/zfs. Может там чего-нибудь дельного посоветуют.
Здравствуйте.
Прилетело вчера linux 6.1.1.arch1-1 и под ним колесо мыши слишком быстрое.
Загружаюсь под linux-lts 5.15.85-1 - а тут всё хорошо, привычная скорость прокрутки от колеса.
Т.е. - не меняется вообще ничего, кроме самого ядра.
А как посмотреть/сравнить состояние системы под разными ядрами? Что-нибудь вроде сделать снимок /sys/devices/system?
Это же должно быть что-то про частоту опроса устройства, нет?
Нужен под микросервер, пойдет и arm, лишь бы была поддержка 15-pin sata т.е. с питаловом, чтобы тупо воткнуть любой диск.
freeorion
Oolite
Colobot
freecivac (Alpha Centauri)
Orbiter
Alien Legacy
Elite Dangerous [1]
mass effect: andromeda
Star Cirizen
EVE Online
kerbal space program
UFO: Enemy Unknown
Lunar Lander
UPD: ранее были темы:
2020, Космические игры на linux
2017, есть ли космическая игра такого плана ?
А вы что посоветуете? Пишите.
Хотелось бы поближе к реальности - реальные звёзды, земная экономика и космодромы. Но просто «калькуляторы звёздного неба» типа stellarium это мало.
Добрый день, может кто знает, пользователю на почту приходят из 1С задача с ссылкой на эту задачу e1c://server/srv-1c… Для Windows, если внести правку в реестр, то можно прям из почты, нажав на эту ссылку открыть её в приложении 1С, а как быть на Linux (Astra) ? Можно ли сделать, чтобы из почты по этой ссылке открывался 1С ?
После начала известных событий мой зарубежный ВПН довольно быстро загнулся. Оплату по картам заблочили, и надо было что-то решать.
Тогда оплатил российский говнохостинг за 2$ в месяц и поднял свой ВПН, в надежде что эта лажа с блокировками меня обойдет. Нашел на лоре готовый скрипт, который помог по-быстрому поднять и настроить ВПН на серваке. Худо-бедно ВПН крутился полгода, но в сентябре настала ему жопа.
Первым конечно поднасрал Росхреновтелеком. В сентябре начал рандомно обрубать мне ВПН время от времени. Потом и вовсе подключиться не получалось к своему серваку. Перешел на другой хостинг, купил новый сервак, сменил OpenVPN на Wireguard, еще пару недель поработало, потом все - наглухо.
Попробовал то же на МТС, вроде работало нормально, но в декабре и он стал обрубать ВПН.
Летом настраивал ВПН другу на Qwerty, в октябре звонит, говорит нифига не работает.
Недавно попросил знакомого из США оплатить мне на месяцок несколько популярных зарубежных ВПНов. Ни один из них толком не работает в России. Может у каких-то мелких отдаленных провайдеров и работает, но Росхреновтелеком люто глушит.
Различные советы и костыли, которые советовали на лоре, перестали помогать. Но вроде не слышно особых массовых воплей по этому поводу. Все уже смирились? Или у всех все работает?
Да, у меня опять обострение хацкерства.
В общем, вытягиваю из SAM’а десятой винды samdump’ом хеши, направляю вывод в файл, вырезаю все остальные строки, кроме одной интересующей вида:
Username:1001:hash1:hash2:::
К своему стыду не знаю смысл 1001.
Скармливаю john’у с --format=NT (емнип NT всегда было, с LM попробовал - то же самое) и --show:
Username::1001...
1 password hash cracked, 0 left
Пароля нет. А винда пустой пароль отвергает.
В отчаянии полез сюда(только потому что это - первая ссылка в гугле). Говорит первый хеш формата LM, второй - NT, на оба выдает пустой результат с успехом.
Что я делаю не так?

Небольшая новость в преддверии свежей beta-версии Haiku.
Илья Чугин (@X512) портировал реализацию протокола Wayland, через которую стало возможно запускать GTK-приложения на Haiku. Данный слой совместимости использует модифицированный код libwayland. Он предоставляет библиотеку libwayland-client.so, совместимую с API и ABI, которая позволяет запускать приложения Wayland без изменений. Cервер работает не в отдельном процессе, а в виде аддона (плагина) в процессе приложения. Для этого была адаптирована библиотека libwayland-client.so. Вместо сокетов в сервере используется нативный цикл обработки сообщений на основе BLooper.
( читать дальше... )
>>> Подробности (haiku-os.org)
Недавно всплывал вопрос о поиске одинаковых картинок. Я хотел применить ImageMagick, но сломал голову его инструкцией и решил начать с решения попримитивнее. Питон 3.10 с установленными пакетами NumPy, Pillow и python-magic. Каждая картинка конвертируется в 24-битную 20x20, затем считается евклидово расстояние между каждой парой картинок (как корень из суммы квадратов разностей для каждого байта). Дефолтное MAX_IMAGE_PIXELS оказалось недостаточным для крупных сканов. Для простоты ограничился типами PNG, JPEG и GIF и файлами только в текущей директории — если нужно что-то сложнее, os.listdir() нужно заменить на соответствующий список или генератор, например,
[os.path.join(root, file) for root, dirs, files in os.walk(os.getcwd()) for file in files] или [r + '/' + f for r, _, files in os.walk('.') for f in files].
import os, magic
import numpy as np
from PIL import Image
thumb_size = 20
max_distance = ( 256**2 * thumb_size**2 * 3 )**0.5
allow_magic = {'PNG image ', 'JPEG image', 'GIF image '}
Image.MAX_IMAGE_PIXELS = 400_000_000
names = sorted( name for name in os.listdir() if os.path.isfile(name) and magic.from_file(name)[:10] in allow_magic )
thumbs = [ Image.open(name).convert(mode='RGB').resize((thumb_size, thumb_size)) for name in names ]
td = [ np.frombuffer(thumb.tobytes(), dtype=np.int8) for thumb in thumbs ]
table = np.full((len(names), len(names)), max_distance, dtype=np.float64)
for nout, hout in enumerate(td):
for nin, hin in enumerate(td[nout+1:]):
table[nout, nin + nout + 1] = np.linalg.norm(hout - hin)
Для идентичных картинок расстояние равно нулю. Для отличающихся размером и артефактами сжатия — существенно меньше 100. Пока ни разу не видел расстояния больше 3500.
Дальше нужно просматривать похожие пары. Дефолтный просмотрщик меня не устроил, поэтому nomacs. Для нулей я вызывал
m = table.min(); r = np.where(table == m); print(m, r);
for x, y in zip(r[0], r[1]): print(names[x], names[y]); os.system( f'nomacs "{names[x]}" & nomacs "{names[y]}"' )
А разобравшись с файлами, заменил все нули на недостижимо большую величину:
table[r] = max_distance
Для расстояний больше 0 вручную повторял однострочник
table[r] = max_distance; m = table.min(); r = np.where(table == m); print(m, r); x, y = r[0]; names[x], names[y]; os.system( f'nomacs "{names[x]}" & nomacs "{names[y]}"'
пока не надоело. В принципе, в таблице могут найтись одинаковые расстояния, поэтому вручную контролировал, что в r вернуло только 1 пару номеров, но этого не произошло.
Для 20 000 картинок, из которых большинство размером 100-1000 пикселов, и которые прочлись в кеш, время вычисления на 1,8 ГГц ядре:
name (определяется magic.from_file) — 10 с,
thumbs (Image.open + Image.convert + Image.resize) — 272 c,
td (np.frombuffer + thumb.tobytes) — 0,3 с,
table — 3276 c.
Как-то улучшить можно? Ускорить?
Использую С++, но очень не удобно, что нет оператора yield. Использую вместо них лямбды для callback, что несколько утяжеляет читаемость кода. У меня их сотни, почти в каждой важной процедуре. В С++ есть какой-то не натив yield, там то же все переусложнено, и еще асинхронность хочет, что уже совсем не то.
На Питоне я еще не пробовал, но вроде он интерпретируемый, а не компилируемый, что не годится. Будет медлено. Или может есть нормально компилируемый? Питон, так же как R, они вроде больше под использование существующих в них библиотек, и не годятся, если хочешь свои тяжелые алгоритмы делать.
Вроде можно попробовать совмещать Python и С++, но пока не решился. Да и те же самые yield из С++ все равно в питон не отправлю.
И вот вопрос, какие могут быть варианты из компилируемых, что бы удобно было делать статистические расчеты на нем?
Нужны yield, нужны лямбды. Д.б. под линукс.
| ← назад | следующие → |
{kind=link}
{kind=link}
{kind=link}
{kind=link}