больше интересует не ссылка, а ваше мнение. Для меня это синоним слова админ.
←
1
2
3
4
5
6
7
8
9
10
→
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от anc

Ответ на:
комментарий
от adn
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от anc
Ответ на:
комментарий
от anc
Ответ на:
комментарий
от adn

Ответ на:
комментарий
от adn
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от anc
Ответ на:
комментарий
от adn

Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от s-warus
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10

Ответ на:
комментарий
от adn
Ответ на:
комментарий
от thesis
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от adn
Ответ на:
комментарий
от thesis
Ответ на:
комментарий
от anc
Ответ на:
комментарий
от windows10
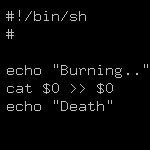
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от anc
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от thesis
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от thesis
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от Stanson

Ответ на:
комментарий
от anc
Ответ на:
комментарий
от Gonzo
Ответ на:
комментарий
от windows10
Ответ на:
комментарий
от sanyo1234
Закрыто добавление комментариев для недавно зарегистрированных пользователей (со score < 50)
Похожие темы
- Форум Admin -> DevOps rename (2024)
- Форум junior devops (2019)
- Форум Эволюция DevOps (2017)
- Форум ищу подработку админом/devops (2018)
- Форум Просветите тёмного (2005)
- Форум Админы вымерли, появились DevOps (2014)
- Форум Посоветуйте ОНЛАЙН курс по DevOps (2018)
- Форум DevOps (2017)
- Форум DevOps (2015)
- Форум Просветите (2006)