Компания JetBrains открыла модель Mellum2, предназначенную для использования в AI-инструментах для разработки ПО. Модель опубликована под лицензией Apache 2.0, веса доступны на Hugging Face. В JetBrains подчёркивают, что Mellum2 обучалась с нуля и рассчитана не на мультимодальные задачи, а на работу с текстом и кодом: маршрутизацию запросов, RAG-конвейеры, суммаризацию, вспомогательных агентов и приватное развёртывание в инфраструктуре компаний.
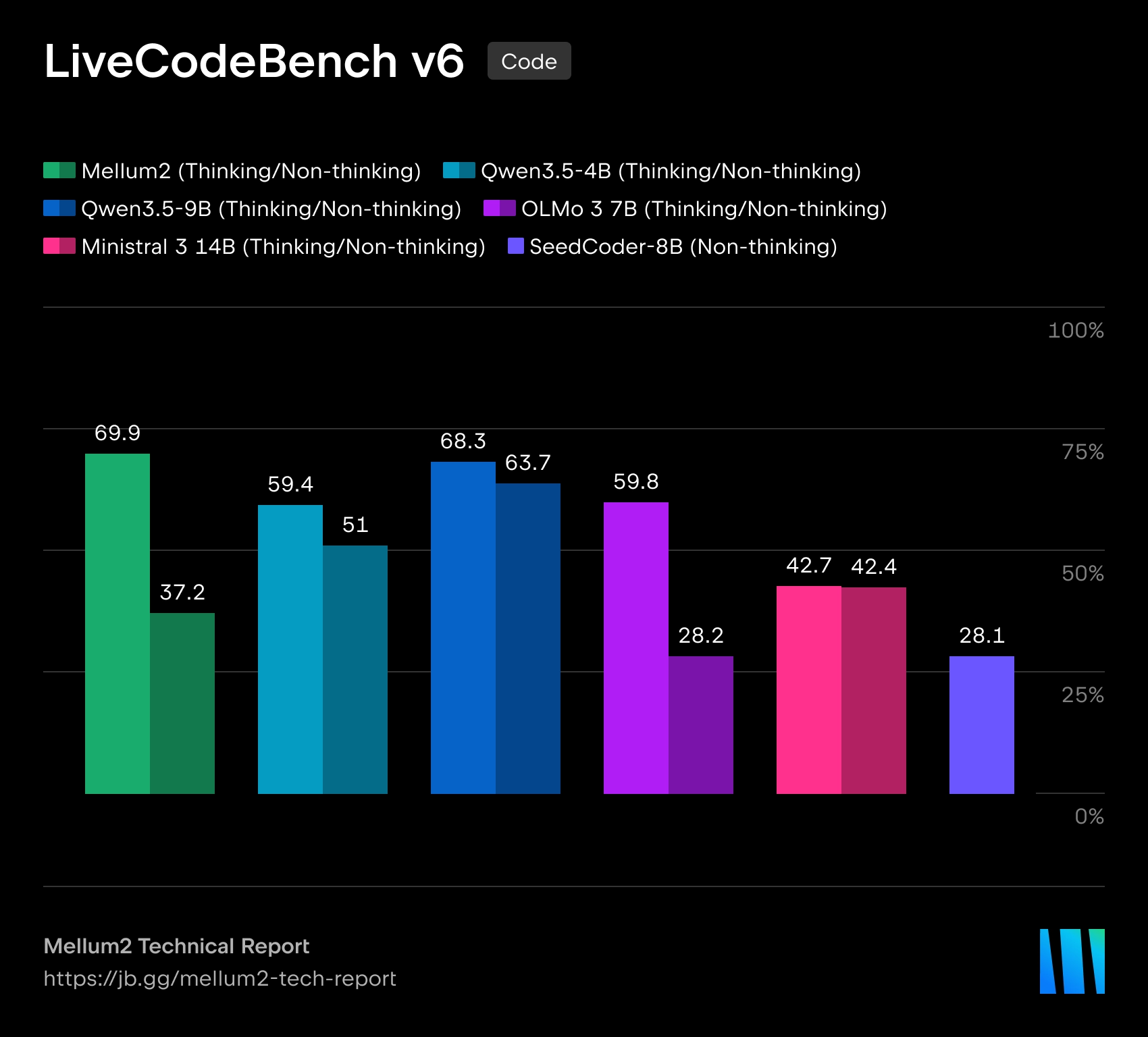
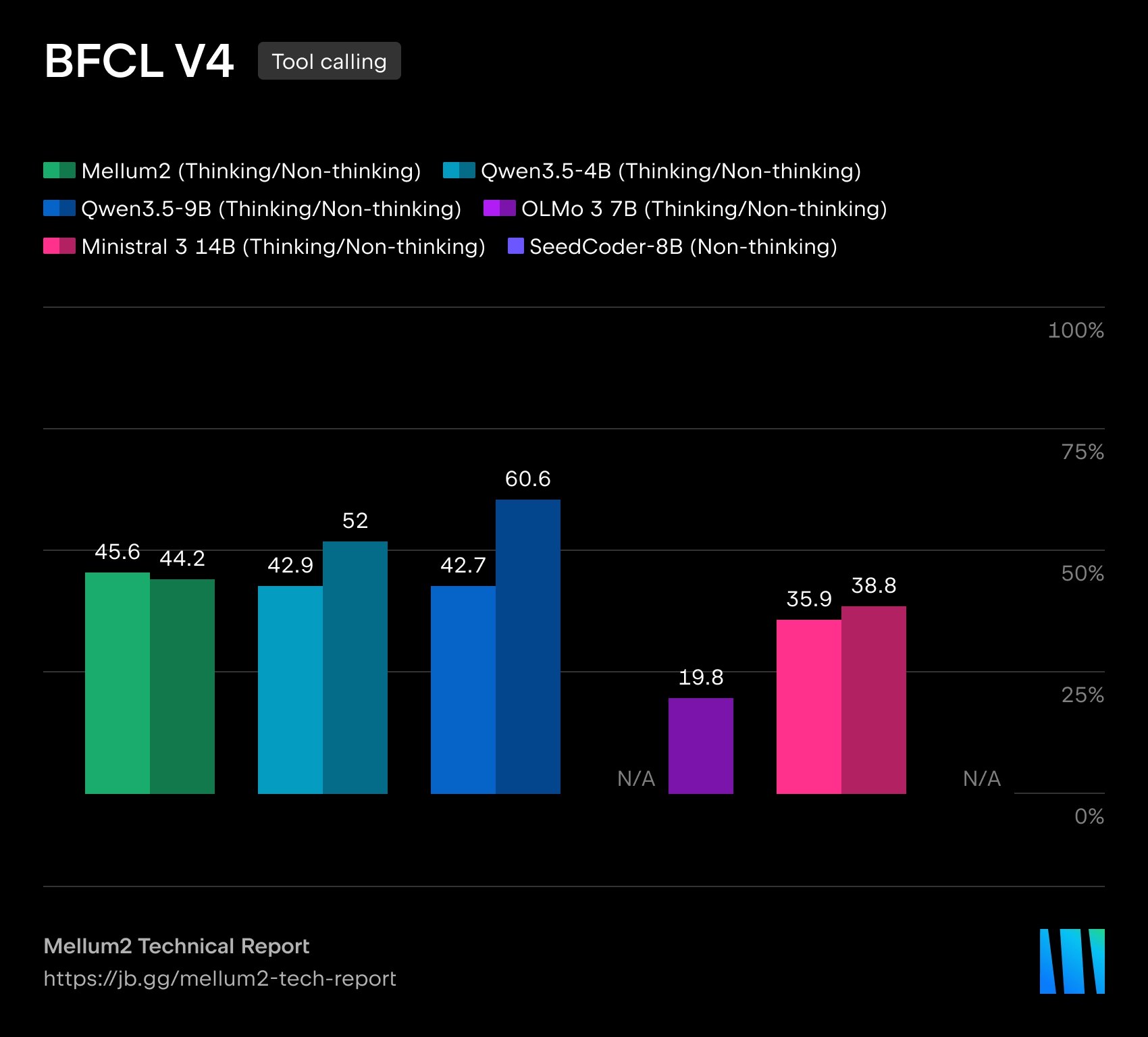
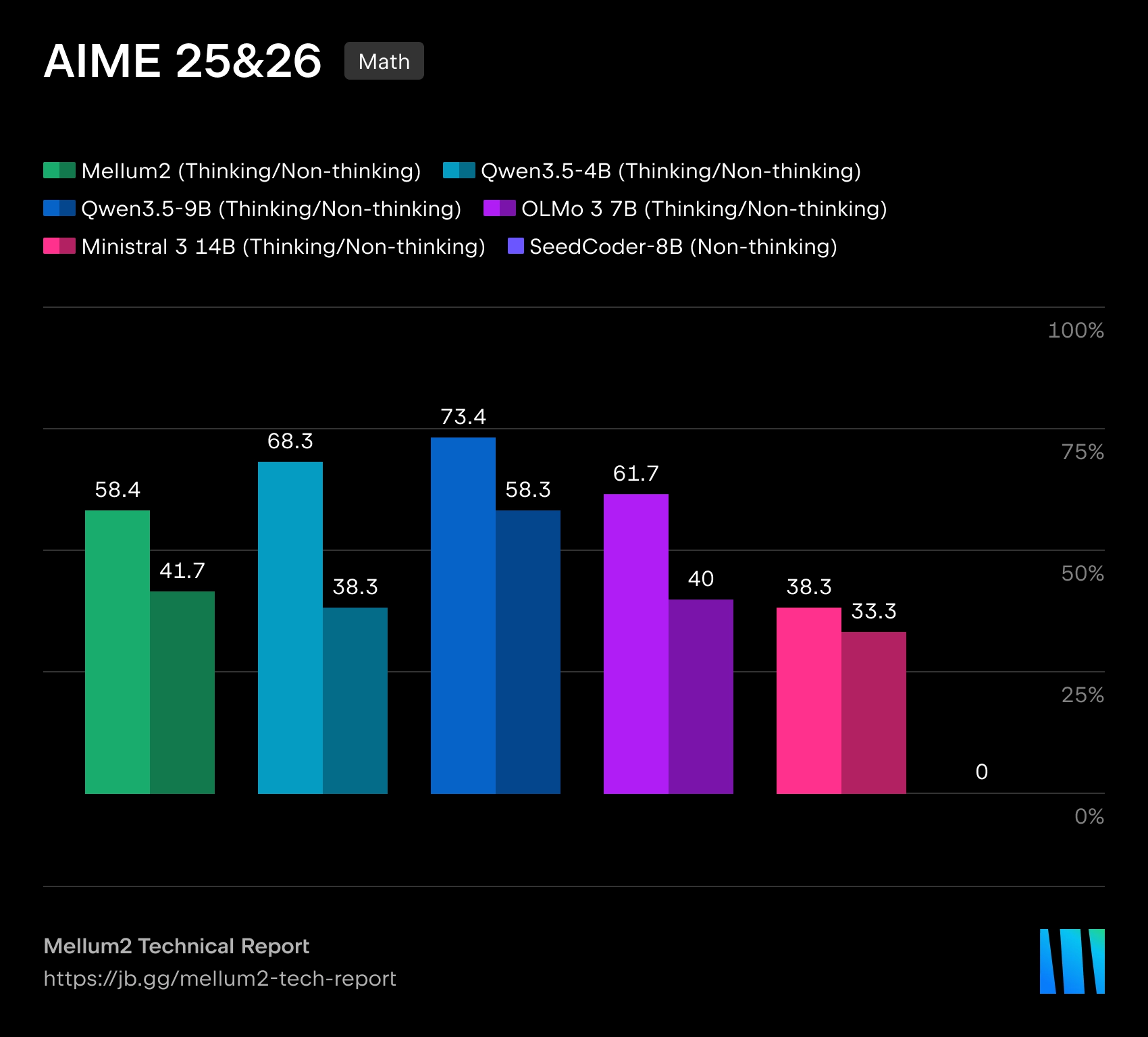
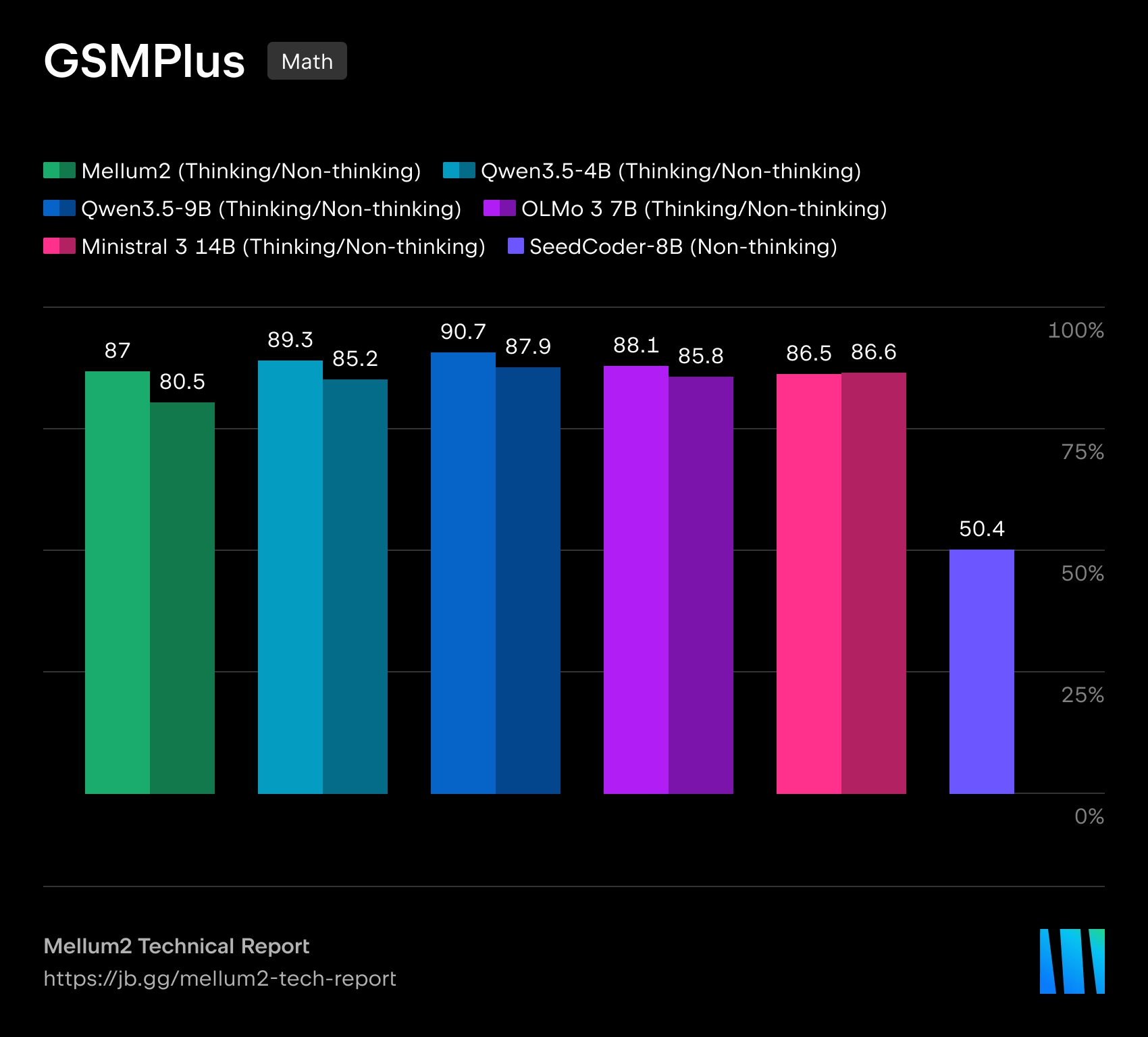
Mellum2 построена по архитектуре Mixture-of-Experts. При общем размере в 12 млрд параметров на каждый токен активируется только около 2.5 млрд параметров, что должно снижать вычислительные затраты и задержки при инференсе. По утверждению JetBrains, по производительности на бенчмарках модель сопоставима с открытыми моделями близкого размера, но обеспечивает более чем двукратное ускорение инференса.
В JetBrains называют Mellum2 развитием первой модели Mellum, которая изначально создавалась для автодополнения кода. Новая версия расширена до более широкого класса задач, где требуется работать как с программным кодом, так и с естественным языком. Компания позиционирует Mellum2 как «фокусную» модель — не замену крупным универсальным LLM, а быстрый специализированный компонент для частых промежуточных операций внутри сложных AI-систем.
Среди предполагаемых сценариев использования называются классификация и маршрутизация запросов между моделями и инструментами, сжатие и обработка контекста в RAG-системах, подготовка данных для агентов, планирование, проверка промежуточных результатов и локальный запуск в средах, где нельзя отправлять исходный код или внутренние данные во внешние API.
На Hugging Face опубликована коллекция Mellum 2, включающая несколько вариантов модели: Thinking, Instruct, Thinking-SFT, Instruct-SFT, Base и Base-Pretrain. Модели распространяются в формате Safetensors по лицензии Apache 2.0.
Для запуска приведены примеры использования через Transformers, vLLM, SGLang и Docker Model Runner.
Технически более интересным выглядит не сам факт появления очередной открытой модели для кода, а выбранная JetBrains ниша. Компания делает ставку не на конкуренцию с самыми крупными универсальными моделями, а на дешёвые и быстрые компоненты, которые можно встроить прямо в IDE, внутренние ассистенты, корпоративные RAG-системы и агентные конвейеры. Для разработчиков и компаний это означает возможность запускать часть AI-логики локально или на собственных серверах, сохраняя контроль над кодом, данными и стоимостью инференса.
>>> Источник