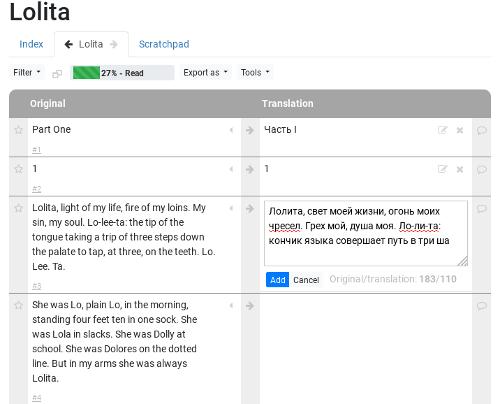
tl — кроссплатформенное веб-приложение с открытым кодом (GitLab) для переводчиков художественной литературы. Приложение бьёт загружаемые тексты на фрагменты по символу новой строки и располагает их в две колонки (оригинал и перевод).
Основные изменения:
- Плагины времени компиляции для поиска слов и словосочетаний в словарях;
- Пометки в переводе;
- Общая статистика по переводу;
- Статистика сегодняшней (и вчерашней) работы;
- В фильтре по содержимому теперь можно использовать регулярные выражения (RE2);
- Если нажат Ctrl при создании варианта перевода, оригинал копируется в перевод;
- Экспорт на notabenoid (и его клоны), импорт с него, обновление, сравнение;
- Ссылки на следующую и предыдущую книгу в режиме перевода;
- Фильтр по названию на главной;
- Поиск и замена с предварительным просмотром изменений;
- Плагин для поиска по уже переведённому (по всем книгам);
- И другое.
>>> Подробности





