Есть гигантских размеров (порядка 125 Гб) текстовый файл, в первых 1000 строках которого нужно сделать замену, не перезаписывая остальные 10^9 или сколько там строк.
Вопрос: как это сделать sed'ом, а если не sed'ом, то чем?
Дело в том, что sed, судя по всему, в режиме -i тупо копирует файл строка за строкой, а под конец «магически» заменяет старый файл новым. Соответственно, если в sed сделать q, то файл оборвётся на той строке, на которой был сделан q, а если q не делать, то придётся ждать до посинения, пока sed героически перезапишет 150Гб на диске. Ну ок, предположим, что для дозаписи данных (а именно это, к сожалению, мне и нужно), так или иначе всё равно придётся перекорячить весь файл, но вот а если бы мне нужно было, скажем, символ B на символ А в первых 200-ах строках поменять - ведь для этого очевидным образом перезапись всего файла не требуется: достаточно лишь прочитать первые 200 строк и поменять один байтик на другой...
Ответ на:
комментарий
от cinyflo

Ответ на:
комментарий
от NeXTSTEP

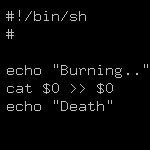
Ответ на:
комментарий
от NeXTSTEP
Ответ на:
комментарий
от beastie
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от sdio




Ответ на:
комментарий
от kovrik
Ответ на:
комментарий
от proud_anon
Ответ на:
комментарий
от NeXTSTEP
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от kovrik

Ответ на:
комментарий
от anonymous
Ответ на:
комментарий
от DRVTiny

Ответ на:
комментарий
от DRVTiny

Ответ на:
комментарий
от beastie
Ответ на:
комментарий
от DRVTiny
Ответ на:
комментарий
от shell-script
Ответ на:
комментарий
от kovrik
Ответ на:
комментарий
от MikeDM
Ответ на:
комментарий
от DRVTiny

Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
Похожие темы
- Форум Отредактировать PDF (2019)
- Форум Кнопка «Отредактировать» (2012)
- Форум Отредактировать *.torrent (2007)
- Форум Отредактировать PDF (2010)
- Форум отредактировать pdf? (2010)
- Форум Зачем трогать паспорт? (2019)
- Форум Отредактировать правило PolicyKit (2018)
- Форум Помогите отредактировать файл (2017)
- Форум Как отредактировать ~/.xinitrc (2012)
- Форум отредактировать gtk тему (2008)