Состоялся выпуск 8.0.0 библиотеки simdutf.
Библиотека предоставляет быстрые SIMD-оптимизированные функции Unicode:
- проверка строк ASCII, UTF-8, UTF-16LE/BE и UTF-32, с идентификацией ошибок и без неё;
- транскодирование Latin1 в UTF-8, UTF-16LE/BE и UTF-32, с идентификацией ошибок и без неё;
- подсчет символов в строках UTF-8 и UTF-16LE/BE;
- перекодирование binary <-> base64, с URL-кодированием или без него;
- изменение порядка байтов строк.
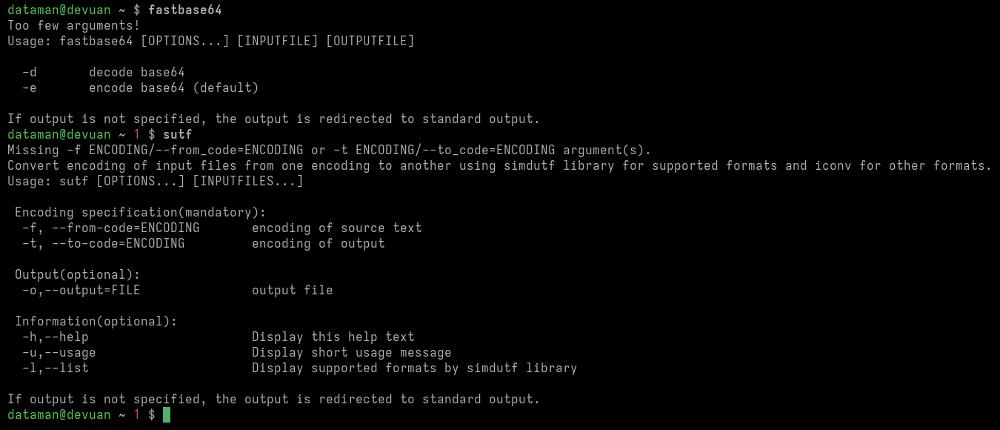
Библиотекой также предоставляются консольные утилиты fastbase64 и sutf.
Основным изменением в этой версии является поддержка constexpr большинством функций библиотеки, то есть они могут выполняться во время компиляции. Например, вы можете проверить, что строка является правильной в кодировке UTF-8 во время компиляции:
static_assert(simdutf::validate_utf8(s));
Возможность использования constexpr требует поддержки компилятором стандарта C++23.
Ещё одним важным изменением является добавление C API. Теперь вы можете легко вызывать simdutf из C (хотя вам по-прежнему необходимо линковаться с библиотекой C++, либо статически, либо во время выполнения). C API должен упростить написание обёрток для simdutf из других языков программирования. Теперь C-заголовок будет входить в релизы библиотеки.
Другие значительные изменения:
- исправлена ошибка в функции
utf8_length_from_utf16()дляbig endian; - добавлена совместимость с std::text_encoding (C++26);
- доработаны функции в
encoding_types.h; - исправлена ошибка переполнения буфера в функции
convert_utf16_to_utf8_safe; - произведены обновления и оптимизации для Loongson;
- улучшено тестирование.



