Недавно для родственников нужно было распознать большой объем медицинского текста на русском языке (с латинскими словами, само собой). Вначале решил поискать в интернете может эти тексты есть. Оказалось, что данный текст представляет собой компиляцию из более других текстов, с замененными и частично переставленными словами. Именно тот текст, который нужен, в инете в явном виде нет. Надо было либо тупо перепечатать, либо распознать.
Под рукой пиратского дистриба Fine Reader не оказалось. Решил попробовать распознать каким-нибудь опенсорчным распознавателем. Выяснилось, что официально с русским текстом на данный момент не работает ни одна опенсорчная система OCR.
Но для гугловской OCR Tesseract, товарищи из группы Tesseract-ocr-russian (http://groups.google.com/group/tesseract-ocr-russian) своими силами подготовили архив с настроечными файлами для распознавания шрифта в стиле Times New. Так как текст, который надо было распознать, был набран похожим шрифтом, я попробовал поработать с этой распознавалкой.
Для работы мне потребовалось
исходники системы Tesseract v.2.01
http://tesseract-ocr.googlecode.com/files/tesseract-2.01.tar.gz
и файлы распознавания русского языка
http://tesseract-ocr-russian.googlegroups.com/web/TimesEnd.tar.gz
Скомпилировал исходники, установил, скопировал файлы русского языка. Отсканировал текст, почистил его немного, перевел в двухбитовый TIFF формат и дал команду
# tesseract image.tiff output -l rus
В ответ была выдана ошибка
unicharset.cpp:67: failed assertion `ids.contains(unichar_repr, length)'
Оказывается, это известная ошибка, появляется только на русских текстах, разработчики о ней знают и советуют либо обнулить файл DangAmbigs, либо исправить в исходнике reject.cpp строку 63. Подробнее здесь http://groups.google.com/group/tesseract-ocr-russian/browse_thread/thread/7ced0bd2c14946d8
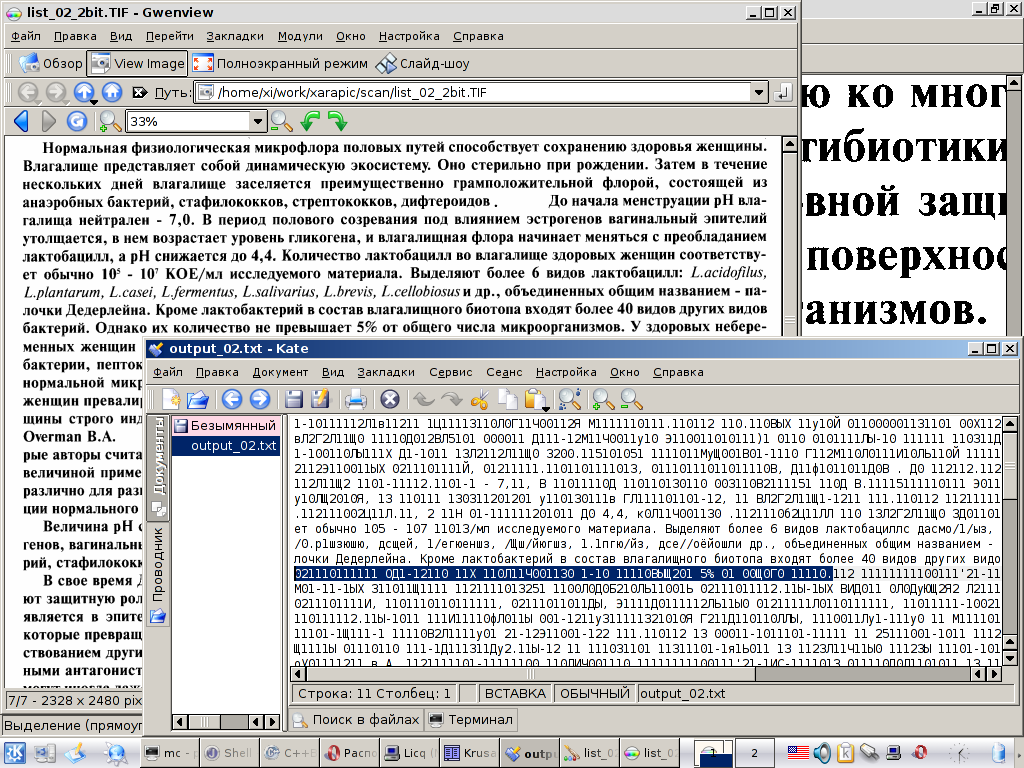
Файл DangAmbigs оказался пустым. Пришлось исправить в исходнике строчку. Пересобрав программу, снова запустил tesseract. На этот раз ошибки небыло. И я с интересом полез смотреть файл output.txt.
Результат вы видите не скриншоте.
Вначале я подумал, что кривость практически всего текста - это следствие кривого преобразования кодировки где-то в недрах Tesseract.
Потом подумал, что наличие правильного куска текста в середине - это следствие неточного определения расстояний между строк. Там где строки распознались - область, где расстояние между строками попало в усредненное расстояние для всего экземпляра. В других строках - в начале текста было, например меньше, а после области с нормальным распознованием - больше.
А потом я внимательно посмотрел на эту криптографию и понял, что на самом деле все распознается.
вЛ2Г2Л11Щ0 - да это же "влагалищо"!
1-100110ЛЫ111Х Д1-1011 - а это "нескольких дней".
Таким образом, вот что можно сказать об этой системе распознавания
- При определении символов, приоритет отдается цифрам... Строки с русским текстом за текст не считаются.
- Строки с русским текстом за текст будут считаться, если в строке будут латинские символы (или, возможно, цифры). При этом сами латинские символы не распознаются.
- Система не умеет работать одновременно с двумя языками. В системе предполагается, что текст набран на одном языке.
- Плохой результат, воможно, связан с исправлением исходника. Исправление нацелено на отключение различия латинской "О" и нуля. Возможно из-за этого, все буквы "О" в строках определяются как нуль, а окружающие символы в группе (слове) тоже пытаются трактоваться как цифры. А если исходник не исправлять, тогда распознавания не будет вообще из-за ошибки, указанной выше. В общем, замкнутый круг.
- Распознавание даже мелкого текста при сканировании в разрешении 300dpi проходит хорошо. Символы степени 5 и 7 распознались без проблем.
Вердикт - в данный момент система Tesseract для кириллицы сыра даже в консольном варианте, и требует доводки.
Распознавание русского текста в Tesseract (OCR от Google)