Здравствуйте!
Хочу представить на обозрение результаты месяца разработок, а именно язык представления результатов парсинга Neparsy.
Парсинг — это первый этап компиляции любого языка программирования, преобразование текста программы в синтаксическое дерево. После разбора в такое дерево у компилятора ещё много дел: провести семантический анализ, оптимизации, преобразование в ассемблер/машинный код. Идея разбить создание компилятора на несколько частей не нова: компиляторы LLVM состоят из фронтенда, компилирующего язык в универсальный ассемблер некого обобщённого процессора, и бекэнда, производящего оптимизации и преобразование в код целевой архитектуры. Neparsy пытается подойти к задаче с обратной стороны и облегчить разработку именно фронтенда. Он создаёт новый слой абстракции где парсинг уже произведен. Внутри такого слоя облегчается задача трансляции между языками. Разновидности языка Neparsy для представления результатов парсинга различных языков программирования называются диалектами. Например, разрабатываемый в настоящее время диалект для языка D обозначается Neparsy:D.
Разработка компилятора нового языка может быть значительно облегчена, если использовать трансляцию между диалектами Neparsy.
Язык Neparsy имеет очень простой для парсинга Lisp-подобный синтаксис (менее 200 строчек для парсера, для сравнения парсер языка C на bison занимает около 3000 строк).
Вкратце суть Neparsy на примере вызова функции и ещё одной постфиксной функции выглядит так:
(function arg1 arg2 arg3).(postfix-function arg1 arg2)
Помимо этого он имеет одну хитрость:
(func (. arg1 arg2).multi-postfix)
Что аналогично навешиванию постфиксной функции сразу на несколько аргументов, т.е.:
(func arg1.multi-postfix arg2.multi-postfix)
Помимо названия функции или оператора в начале скобки указывается тип через # и метка через @:
(*#unary@label pointer)
Язык не вводит собственных ключевых слов, а использует для этого #типы. Например:
(#. str f1 (#[ 2) f2)
Означает str.f1[2].f2
(#" Литерал строки с пробелами)
А вот пример if-else-if-else конструкции:
(#if
(условие1).(#body ветка1)
(условие2).(#body ветка2)
(#else).(#body else-ветка))
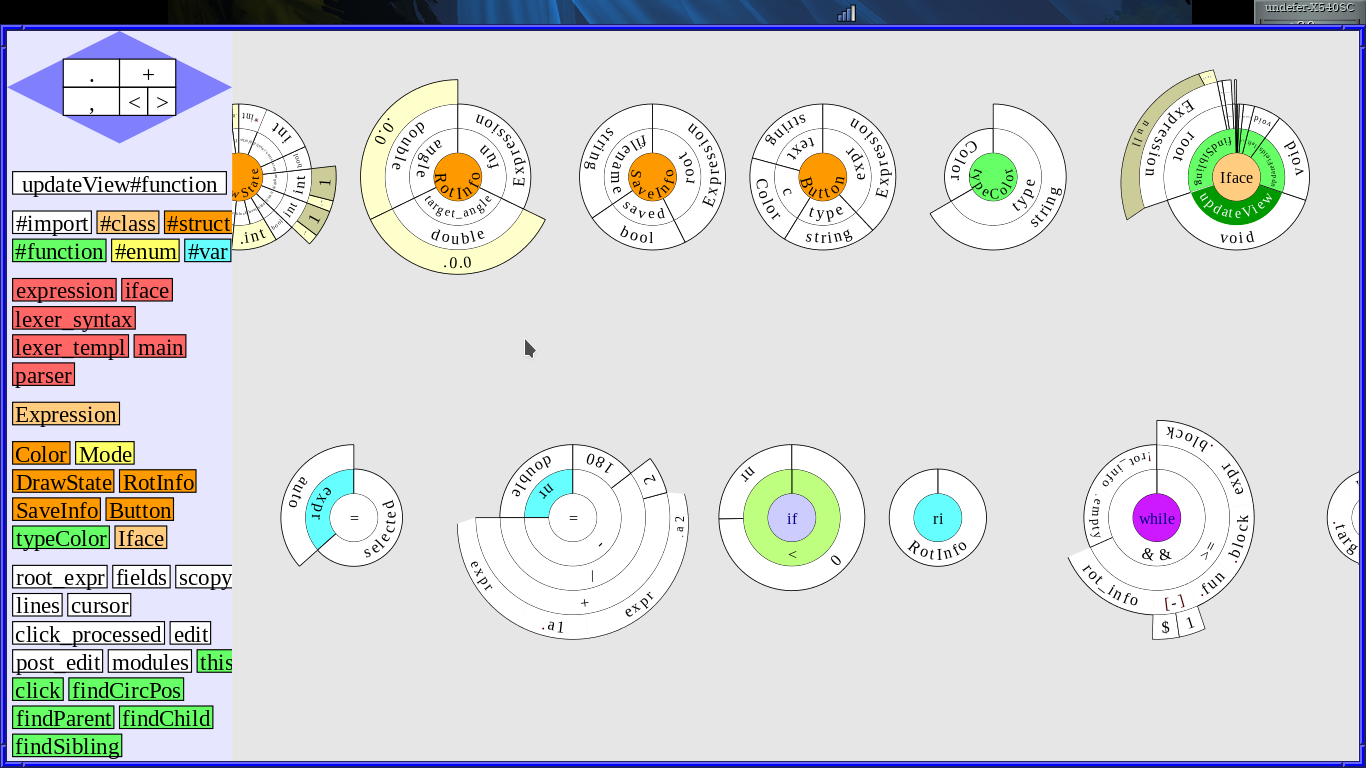
Neparsy также имеет оригинальное графическое представление в виде круговых диаграмм, что и представлено на скриншоте.
За месяц удалось написать:
- Редактор круговых диаграмм, с клавиатурным управлением. Поддержка мыши — начальная.
- Парсер кода D, того подмножества D на котором написан сам Neparsy. Причём лексический анализатор и парсер написаны (нарисованы?) непосредственно в редакторе Neparsy.
Репозиторий проекта на github: https://github.com/unDEFER/neparsy
Ветка на языке neparsy: https://github.com/unDEFER/neparsy/tree/neparsy
На скриншоте можно видеть: 4 структуры, функцию typeColor, класс Iface в котором развёрнута функция updateView, а в ней инициализацию двух переменных (большое выражение: double nr = (expr.a1 + expr.a2)/2 - 180), блок «#if», ещё одну переменную ri без инициализации, блок «#while».
В левой панели видны видимые в текущей точке кода переменные и типы. Также там появляется круговая диаграмма с помощью, которой можно бродить по полям и подполям структур.
Управление:
- Стрелки — навигация
- Запятая — добавить дочерний узел
- Пробел — добавить братский узел
- Точка — преобразовать узел в дочерний
- Ctrl+Запятая — добавить постфиксный узел/расширить его влияние на узел влево
- Ctrl+Точка — добавить постфиксный узел/сузить его влияние на узел вправо
- Shift+Влево, Shift+Вправо — Переместить текущий узел влево или вправо.
- Ctrl+Стрелки — навигация по полям (когда диаграмма полей видна внизу левой панели)
- Del — удалить узел и всех потомков
- Ctrl+Backspace — «отстричь» потомков
- Ctrl+S — сохранить в формат neparsy
- Ctrl+D — сохранить в .d-формат (@D модули)
- Ctrl+L — сгенерировать лексический анализатор из файла описания синтаксиса (@Lexer модули)
- Enter/Escape — выход из режима редактирования узла
Помимо трансляции между языками есть надежда, что редактор круговых диаграмм окажется удачным решением интерфейса для IDE для мобильных устройств.

