Есть сетевое приложение, снял трейс с помощью perf, вышло, что 35% ЦПУ оно проводит в приеме сообщений, 50% в передаче. Передается порядка 110 сообщений в секунду размером в основном от 100 до 500 байт. Т.е. данных явно мало и нагрузка на ЦПУ явно этому не соответствует. Нужно разобраться почему так.
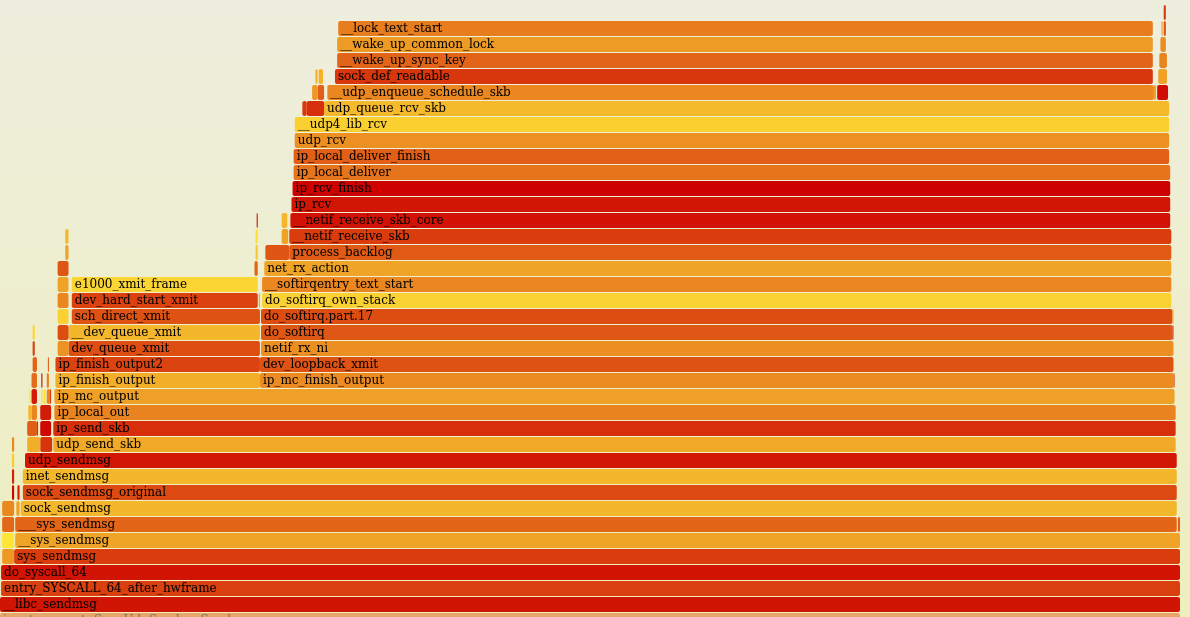
Что бросается в глаза - в приеме только 5% из 35% оно проводит в сисколах ядрах, а при передаче уже 26% из 50%. Разве так должно быть? И самое главное - из 26% ЦПУ, что уходят на _libc_sendmessage (которая уже дергает ядро), около 19% уходит на ip_recv - это же по идее уже прием данных, а не передача? а вообще стек вызова заканчивается вызовом __lock_text_start, где ЦПУ проводит 17.8% времени
есть знатоки линукса и его ядра, кто может пояснить: 1 Нормально ли тратить при передаче 100 сообщений в 100-500 байт столько ЦПУ (запускаю на виртуалке, на хосте рязань 9 5950х) 2. Почему в вызове _libc_sendmessage используется ip_recv и в итоге подавляющее кол-во времени проводится в __lock_text_start
Из подробностей - обмен по мультикасту, создается несколько отдельных сокетов, которые привязываются к одному мультикаст адресу, под капотом boost::asio.
UPDATE: добавил ссылку на FlameGraph со стеком вызовов при отравке сообщения. Тут видно, что __libc_sendmessage занимает 9% от общего времени работы приложения, и из них 6.35% ЦПУ проводит в __lock_text_start. Возможно это скажет кому-то из специалистов?






{kind=link}