По работе разбираю очередное творение индусской промышленности, а именно, реализацию амазоновского S3. Поделюсь своими соображениями и интересно было бы услышать ваши.
Недавно Амазон объявил о переходе с модели eventual consistency на strong consistency, то есть read-after-write consistency.
А также есть статья в блоге некоего высокопоставленного манагера из Амазона:
https://www.allthingsdistributed.com/2021/04/s3-strong-consistency.html — Diving Deep on S3 Consistency
Первое, что думается в ответ на эти новости: а как же теорема CAP? Подсказки для этого ответа ищутся в гугле:
https://news.ycombinator.com/item?id=25271791
So they claim performance and availability will remain same while claiming strong consistency. I was confused at first but then “same” availability isn’t 100% availability. So it indeed CP.In this paper about Spanner, we learn that it’s possible to build a CA system (one which prioritises Consistency and Availability) and also build a network so good that the risk of Partitions to be Tolerant of is negligible enough to effectively ignore.Короче говоря, CAP никуда не делось, вечного двигателя, сверхсветовой передачи информации, или телепорта в амазоне не изобрели. Амазон пошел по логичному пути: пока нет ни единого разрыва сети, БД дает consistency+availability гарантии, когда сеть рвется — запросы на запись перестают выполняться, имеющиеся данные замораживаюся в том систоянии, в котором они были до разрыва.
Теперь по самой реализации. Инфа в гугле крайне скудная, пока что лучшее, что удалось найти:
https://www.reddit.com/r/aws/comments/k4yknz/s3_strong_consistency/gecdohv/
If I had to guess, s3 synchronously writes to a cluster of storage nodes before returning success, and then asynchronously replicates it to other nodes for stronger durability and availability. There used to be a risk of reading from a node that didn't receive a file's change yet, which could give you an outdated file. Now they added logic so the lookup router is aware of how far an update is propagated and can avoid routing reads to stale replicas.Судя по всему, ключевым архитектором сего чуда был некто Нихил Шах:
https://www.linkedin.com/in/nikhiljshah/
DATA ITEM AND WITNESS SERVICE PARTITIONING IN A DISTRIBUTED STORAGE SYSTEM
Patent date Filed Oct 1, 2021 Patent issuer and number P73159-US01
TRANSACTION MANAGEMENT FOR MONOTONIC WRITE CONSISTENCY IN A DISTRIBUTED STORAGE SYSTEM
Patent date Filed Oct 1, 2021 Patent issuer and number P74530-US01Первое, что находится в гугле по запросам «strong consistency witness» и «monotonic writes witness» — это статьи:
http://www2.cs.uh.edu/~paris/MYPAPERS/Icdcs86.pdf - Voting with Witnesses: A Consistency Scheme for Replicated Files
https://web.stanford.edu/~ouster/cgi-bin/papers/ParkPhD.pdf - Achieving both low latency and strong consistency in large-scale systems
Первая статья делает акцент на quorum-based консенсусе — это весьма медленная штука и я сомневаюсь, что амазон смог бы отрапортовать про бесплатный апгрейд согласованности данных, если бы оная для простого чтения требовала еще одной круговой задержки по всему кластеру. Из этой же оперы идет статья с модификацией Apache ZooKeeper:
https://www.usenix.org/system/files/fast20-ganesan.pdf - Strong and Efficient Consistency with Consistency-Aware Durability
Здесь авторы просто отложили операции записи, за счет чего уменьшили время ответа по запросам записи до уровня асинхронной репликации (и потеряли гарантии сохранности при исчезновении питания, но кого это волнует в 2022?). Монотонность чтений без необходимости опроса всего кластера «гарантировали» списком активных узлов, которые получили актуальные изменения и знают об этом. Можно спорить по поводу того, вовремя ли отвалившиеся узлы поймут, что у них уже нет актуальных данных, и потому сериализуемы ли чтения по кластеру, но ведь чтения несериализуемы даже в оригинальном ZooKeeper по абсолютно той же причине (узел может продолжать думать, что он лидер, хотя в кластере выбран новый лидер) — так что вроде как ухудшения нету.
Вот я сидел-сидел, думал-думал, и подумал «а зачем здесь полный консенсус?». Соответственно, взор мой возвращается снова на
https://web.stanford.edu/~ouster/cgi-bin/papers/ParkPhD.pdf - Achieving both low latency and strong consistency in large-scale systems
где авторы используют свидетелей просто как избыточное eventual consistency хранилище. Вам ничего это не напоминает? Мне напоминает устройство S3 до введения строгой согласованности.
Лично я склоняюсь к тому, что Амазон под капотом S3 оставил тот же самый eventual consistency, работающий на типичной для той же Amazon DynamoDB модели «sloppy consensus», например, когда у вас 10 узлов в сети и для подтверждения записи достаточно подтверждения от 3 узлов (а не шести, как это было бы в строгом консенсусе). Данные со временем будут раскопированы асинхронно на остальные узлы. Естественно, sloppy consensus никак не защищает от split brain, когда у вас две части кластера теряют связь и начинают независимо изменять файлы (в обоих частях есть по три узла для успешного подтверждения), и потому не знают про изменения в другой части кластера. Очевидно, при восстановлении связи нужно как-то конфликтные изменения разруливать. Amazon DynamoDB и Riak уже давно используют решение «в лоб» — оставлять запись с самым последним timestamp. Ту же политику декларирует S3:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html#Consistenc...
Amazon S3 does not support object locking for concurrent writers. If two PUT requests are simultaneously made to the same key, the request with the latest timestamp wins.Совпадение? Не думаю. По итогу воображается что-то такое:
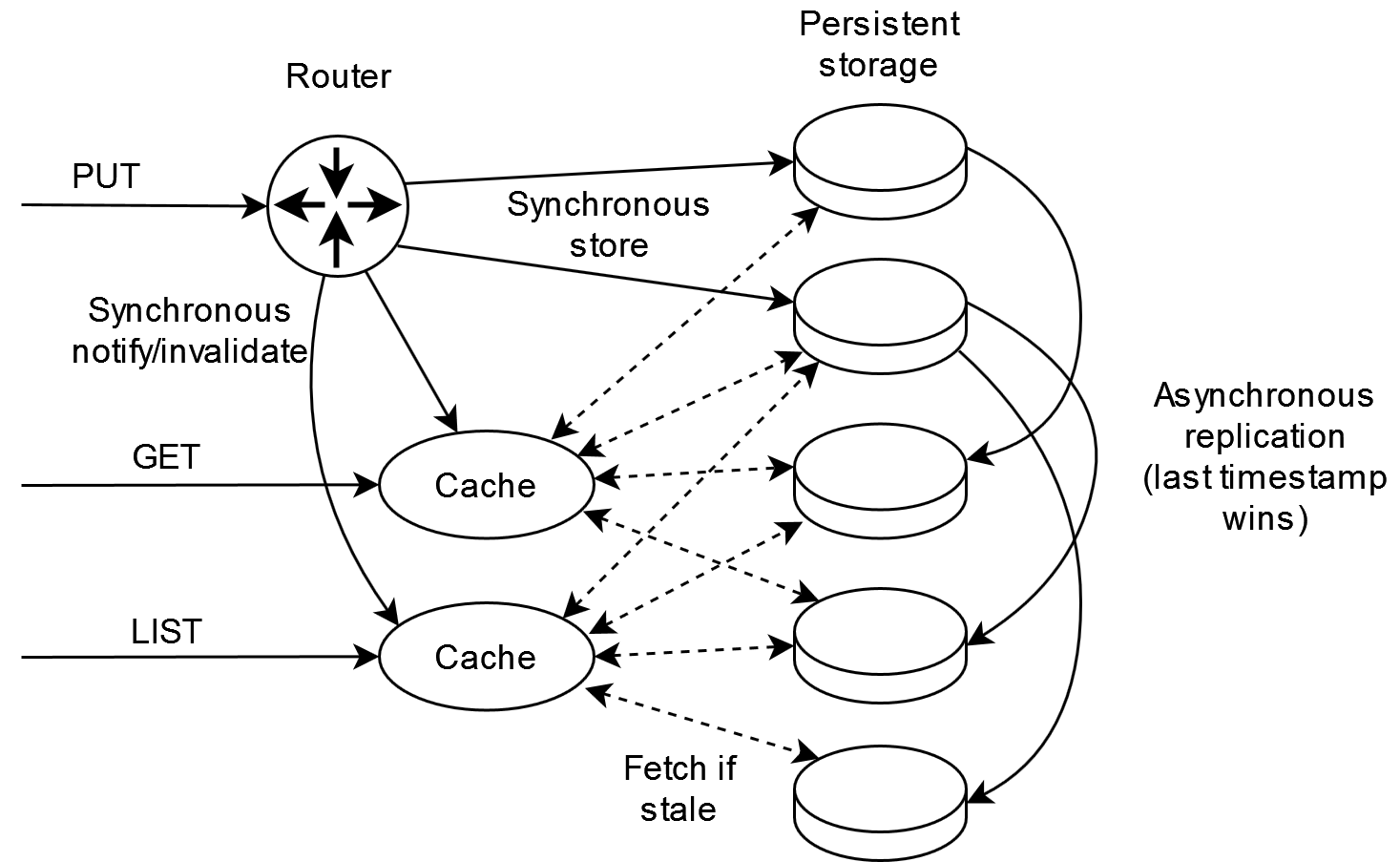
https://habrastorage.org/webt/ve/c9/ua/vec9uatqx1zht2814ljj-ipvipm.png
То есть, по сути то же самое DynamoDB плюс подобие процессорного кэша. Успешный ответ на операцию PUT возвращается только после успешного сохранения на достаточное число персистентных хранилищ и после оповещения кэшей. Операция оповещения кэша требует передачи данных по сети, но лишь самого минимума, и кэш может мгновенно ответить на этот запрос, так что синхронность не является проблемой.
Как можно заметить, я нарисовал четыре стрелки от кэша к хранилищу — это минимальное количество связей, которое нужно для гарантированного получения данных, залитых на 2 из 5 хранилищ. В принципе, используя информацию из оповещения кэш может стучаться только в два первых хранилища, в которые данные будут размещены раньше всего. Конечно, может оказаться так, что данные уже нужны, а они даже в первые хранилища не залиты — это достаточно редкая ситуация, которую можно разрулить через запрос «отдай мне данные версии XXX, если они у тебя уже есть».
Здесь возникает множество подводных камней при потери связи между узлами. Например, кэш может так и не дождаться ответа на «отдай мне данные версии XXX». Но проблема может быть еще серьезнее: что если кэш вообще не получил уведомления и до сих пор считает, будто данные остались в своей старой версии? Вот это и есть вся фишка CAP и недосказанности со стороны Амазона — а ничего не делать, тупо выдавать старую версию файла, хотя уже давно есть новая. Скрестим пальчики и будем надеяться, что ситуация февраля 2017 года больше никогда не повторится.






{kind=link}