Чем отличается компилятор от интерпретатора?
Сабж
Еще интересует, является ли то и другое трансляторами?
Сабж
Еще интересует, является ли то и другое трансляторами?
В институте узнал про язык программирования Lisp. До этого писал только на Паскале и C. Оказывается, там весьма много диалектов: ISLISP, Common Lisp (как я понял, эти 2 устаревшие), Scheme + новые, такие как Clojure, newLisp, Arc. Какой мне выбрать для написания десктопных приложений (я бы хотел сделать свой инструмент для Computer Aided Translation, что-то сравнительно простое на gtk)? Хотелось бы так, чтобы надо было несильно переучиваться, что-то похожее на Pascal.
Мне его порекомендовали за удобство разработки на нём (хотя я не очень сильно понял, в чём разница между разработкой на C и на лиспе).
10 февраля 2014 года игровая студия OKAM выпустила под лицензией MIT игровой движок Godot, как и обещала.
Godot — малоизвестный (т.к. до сегодняшнего дня он не выходил за пределы OKAM), но обладающий большими возможностями движок, по функциональности почти не уступающий одному из «мейнстримов» в геймдевелопменте — Unity (но с ориентацией, прежде всего, на 2D, в отличие от него):
>>> Подробности (Invalid URL, no host part!)

Вобщем, я устал от этой проклятой, ужасной иконки (которая, кстати говоря, зачем-то 24х24 вместо стандартных треевых 22х22), и с горя начал стучать по клавиатуре копытами.
В результате получилось нечто, приводящее мой трей в более-менее приятный вид и делающее меня счастливым. Увы, на клавиатурах в Эквестрии всего две клавиши: Ctrl+C и Ctrl+V, поэтому за качество извиняйте.
Иконки для своей темы тоже вышли не очень, но в последний момент пришел 
MiniRoboDancer и немного помог, сделав иконки терпимыми.
Надо бы еще ебилд выложить, но он все равно слизан с ебилда skypetab-ng, как и почти все остальное.
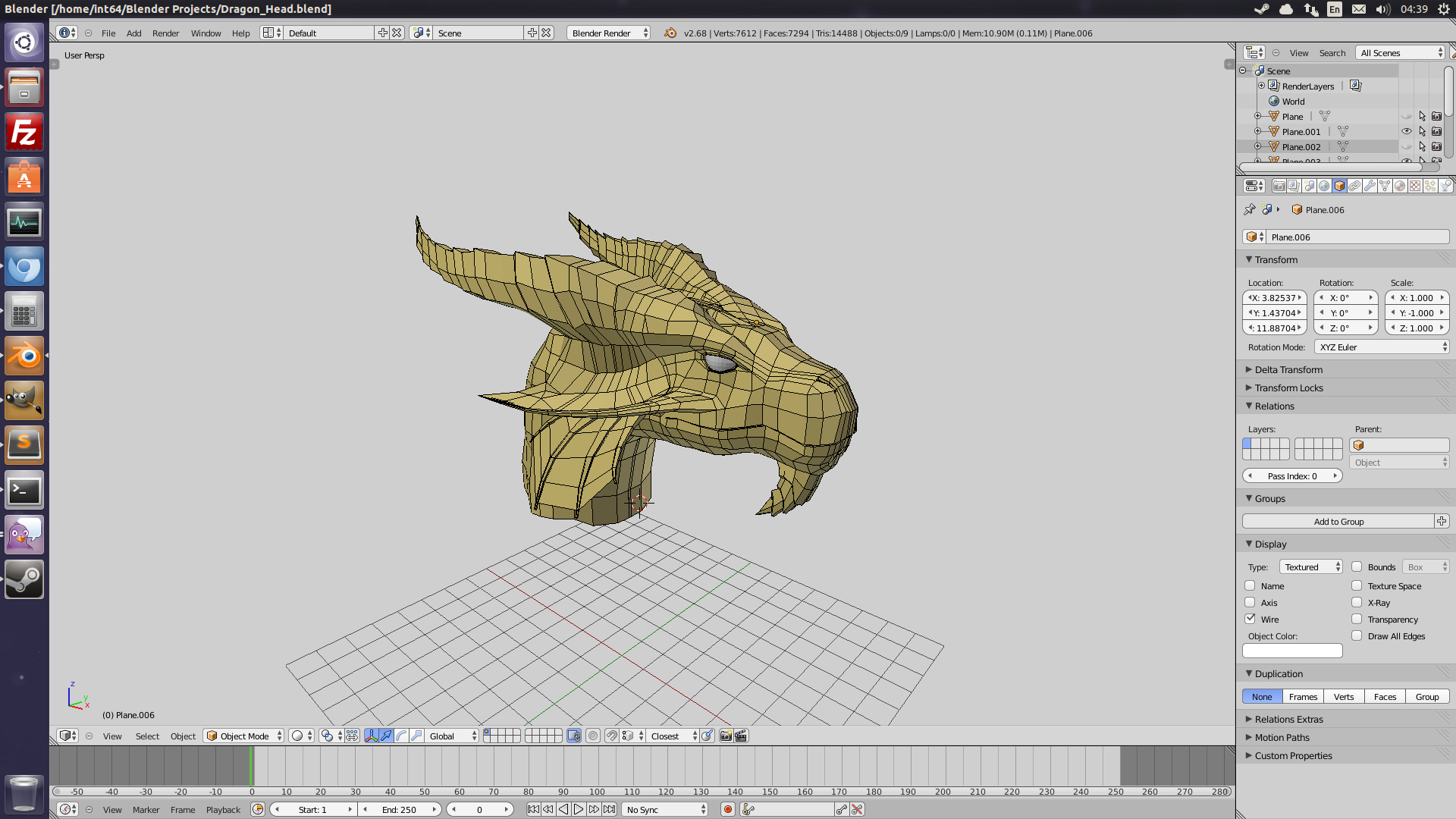
Собственно не кубик )) В светлом блендере работать очень приятно. Перехожу с Maya, и для себя открыл, что в блендере даже удобнее работать, если настроить под себя, а инструменты для моделирования вообще очень понравились, в Maya 8.5 таких не было (не знаю как на счет Maya 2014). И открыл для себя отличный плагин F2: http://blenderartists.org/forum/showthread.php?278787-F2 Надеюсь инструменты для анимации меня так же порадуют :)
Есть функция на Scheme (из sicp):
(define new-withdraw
(let ((balance 100))
(lambda (amount)
(if (>= balance amount)
(begin (set! balance (- balance amount))
balance)
"Недостаточно денег на счете"))))
В теоретической информатике есть такая штука как CK-автомат. Помимо написания заумных статей, у него есть и более приземлённое предназначение. Он позволяет записывать call-by-value макросы в Scheme.
Вот, собственно, он:
(define-syntax $
(syntax-rules (quote)
(($ e) ($ () e))
(($ () 'v) v)
(($ (((! ...) a ...) . s) 'v) ($ s #f (! ... 'v) a ...))
(($ s #f (! va ...)) (! s va ...))
(($ s #f (! ...) 'v a ...) ($ s #f (! ... 'v) a ...))
(($ s #f (! ...) a aa ...) ($ (((! ...) aa ...) . s) a))
(($ s (! a ...)) ($ s #f (!) a ...)) ) )
(define-syntax $cons
(syntax-rules (quote)
((_ s 'a 'd) ($ s '(a . d)))) )
(define-syntax $map
(syntax-rules (quote)
((_ s 'f '() ...) ($ s '()))
((_ s 'f '(a . d) ...) ($ s ($cons (f 'a ...) ($map 'f 'd ...)))) ) )
(define-syntax $filter
(syntax-rules (quote)
((_ s 'p '()) ($ s '()))
((_ s 'p '(a . d)) (p a ($ s ($cons 'a ($filter 'p 'd)))
($ s ($filter 'p 'd)) )) ) )
(define-syntax $quote
(syntax-rules (quote)
((_ s 'x) ($ s ''x)) ) )
(define-syntax ?bool
(syntax-rules ()
((_ #f t f) t)
((_ #t t f) t)
((_ :: t f) f) ) )
(define-syntax ?symbol
(syntax-rules ()
((_ (a . d) t f) f)
((_ #(x ...) t f) f)
((_ a-symbol t f)
(let-syntax
((? (syntax-rules ()
((_ a-symbol tt ff) tt)
((_ else tt ff) ff) )))
(? ! t f) )) ) )
($ ($quote
($map '$cons
($filter '?symbol '(a b 1 2))
($filter '?bool '(3 #t #f 4)) ) )) ===> '((a . #t) (b . #f))
Вобщем такое дело: Я для дела и апгрейда решил заменить свой старый штеуд на новое железо, и потянуло меня что-то на амд, ибо разницы в перфомансе моего штеуда и новомодного i7 нет, но вёдра и более высокая ТТ, а так же нужные мне фичи - сподвигли меня купить что-то.
Вобщем выбрал я fx8350 и уже почти заказал, но братуха говорит, что бульдозер у него делает «буль-буль» и всё пичаль. Мы побенчили и пришли в выводу, что на штуеду по каким-то мистическим причинам память работает намного быстрее, хотя там и там 1600 дефолтные планки.
Братуха стал выдвигать теории о разном устройстве двуканала и прочено, моя вера в амд пошатнулась. И только вы можете меня спасти.
Кто хочет помочь - пожалуйста побенчите и выложите сюда результаты бенчей и свой проц/память - это будет всем интересно. http://www.alasir.com/software/ramspeed/ramsmp-3.5.0.tar.gz - бенч, собираем sh build.sh.
Мне интересные 10,11,(12),16,17,(18) - то, что в скобках не обязательно. Так же, попробуйте -p1,2,3,4,5,6,7,8, пожалуйста.
Так же, люди, кто юзал «новую» «стримовую запись», аля movnt* - как оно? Для многократного обхода данных, непомещающихся в кеш - кеш мне только мешает, поэтому nt запись через буферы меня спасает, но с чтением проблемы - поэтому я решил поверить в sse4.2 и купить себе новое железо.
Поглядел я тут на пацанов и увидел прогресс в их глазах. Поэтому я решил вести тут свой бложик, в котором я буду толкать матчасть, разбирать/разрушать всякие мифы и легенды, а так же их обсуждать с пацанами. Банить меня не надо - тут всё будет очень культурно.
Это будет формат для самых маленьких, где я буду показывать как что-то пилится по-пацаночке. Его задача - на примерах пересказать штеудмануал тем, кому лень его читать, но кто очень любит спорить про код, перфоманс и матчасть. Ну и просто интересные наблюдения.
Изначально я хотел написать про то: что такое бесплатные вычисления на примере is_range() + сумма елементов массива, но тут выявилась смешная особенность, поэтому пока без is_range().
Начнём с простого - сумма елементов(float) массива. Как написать её быстро? Обычный крестопоц сделает так:
auto summ = accumulate(begin(vec), end(vec), 0.)
Этот код выдаёт 5.6GB/s(мы всё бенчим в л1д 32килобайта массив). Казалось бы, если бы мы слушали всяких «гуру», которые нам говорят: accumulate() - оптимизирован, «ты что умнее создатели stl"а?», «конпелятор умнее тебе - сам всё делает оптимально», «руками что-то делать слишком сложно и не нужно» - то мы бы там и остались с этими 5.6ГБ, но мы пойдём дальше и поймём почему так, и является ли это тем, что намн ужно.
Но посмотрев на код - он не векторизован:
addq $4, %rdx
vcvtss2sd -4(%rdx), %xmm2, %xmm2
vaddsd %xmm2, %xmm1, %xmm1
Почему? Патамучто это основная флоатпроблема: Он не ассоциативен - флоат не имеет в себе точных представлений всех чисел входящих в диапазон его «представления» т.е. порядкопроблемы.
Поэтому конпелятор НЕ ВЕКТОРИЗУЕТ флоат по умолчанию, ну никак. Даже такую банальщину.
Для решения этих проблем - есть ключик -funsafe-math-optimizations, который входит в -ffast-math, который кладёт на точность при вычислениях. Добавив его мы получаем уже 44.9GB/s.
Но теперь мы получаем ещё одну проблему - надо думать: «как бэ сунуть эту ключик не повредив там, где этот ключик не нужен».
Поэтому ноцанам, которые хотят быстро и не хоятт рандомных жоп из-за тупости конпелятора - пишут всё руками. Допустим на той же сишке это пишется так:
double memadd_autovec(buf_t buf) { //5.609465GB/s, либо 44.969652GB/s с ffast-math
float * it = buf_begin(buf), * end = buf_end(buf), summ = 0.;
do {
summ += *it++;
} while(it != end);
return summ;
}
double hsumf(__v8sf v) {
return (v[0] + v[1] + v[2] + v[3] + v[4] + v[5] + v[6] + v[7]);
}
double memadd_vec(buf_t buf) { //45.652002GB/s и класть на ffast-math
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ += *it++;
} while(it != end);
return hsumf(summ);
}
Т.е. разницы никакой нет, кроме нужной нам реализации горизантального сложение вектора. Когда я говорил пацану: «векторную сишку для написания быстрого кода юзать намного проще, чем плюсы» - поцан нипонимэ, да и любые пацаны скажут - ну дак с -ffast-math оба выдают по 45гигов - нахрен эта сишка нужна?
А вот зачем:
double memadd(buf_t buf) { //132.878440GB/s
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ += *it++;summ += *it++;summ += *it++;summ += *it++;
} while(it != end);
return hsumf(summ);
}
Это называется пацанский анролл копипастой, а вот заставить конпелятор нормально что-то разанролить очень сложно.
Если бы мы слушали всяких «гуру», которые нам вещают: «анрол говно и не нужен» - мы бы так и седели с 45-ю гигами, а так мы сидим с 132.878440GB/s. Т.е. анролл нам дал немного не мало ~300%.
Но основная мысль, которую толкают всякие «гуру» - это не надо следить за тактами/считать такты и прочее. Но мы о5 сделаем наоборот и посмотрим что будет.
Т.к. наш юзкейс упирается на 99% в throughput и дёргается одна инструкция, то нам достаточно просто считать теоретическую производительность для моего камня. 4.5(частота камня)*8(т.е. у нас камень с avx, то там вектор 32байта, либо 8флоатов.)*1(throughput нашей инструкции - в данном случае vpaddps из интел мануала). Т.е. 36гигафлопс, либо ~144гига. Т.е. мы сняли овер 90% теоретической производительности - остальные 10% у нас ушли в наши циклы, всякие горизонтальные суммы вектора и прочее, ну и конечно же чтение данных из кеша.
Но самое смешное - на моём хасвеле умножение имеет throughput 0.5 - т.е. на хасвеле умножение быстрее сложения. Это новая забористая трава у интела.
Казалось бы - какой жопой сложнее оказалось медленнее умножения - а вот так, на всяких штеудах производительность уже давно зависит не от каких-то технических возможностей, а от маркетинга и хотелок.
Поэтому очень смешно слушать, когда какие-то пацаны говорят: «float point имеет такую же производительность как и инты» - нет, оно имеет такоу же производительность лишь по причине того, что на штеуде инты тормазят так же, как и float.
И чтобы окончательно в этом убедится - мы взглянем на fma(вариации умножения со сложением/вычитанем), которые имеют throughput 0.5 - да, да - на хасвеле умножение+сложение в 2раза быстрее просто сложения. Это уже не просто трава - это что-то принципиально новое.
У целочисленного сложения же throughput 0.5 и казалось бы, если мы поменяем в нашей функции float на int - у нас будет сложение работать в 2раза быстрее, но это не так. Оно выдаёт те же 130гигов, а почему?
Вообще у камня есть такая фича, допустим у нас:
add $1, %reg0//вот тут инструкция add залочит регистр reg0
add $1, %reg0//а эта инструкция уйдёт в лок до особождения предыдущей инструкцией регистра reg0
Чтобы такой жопы небыло - есть специальная фича:
add $1, %reg0//lock reg0
add $1, %reg0//И тут вместо того, чтобы уйти в лок - камень вместо reg0 даёт инструкции любой свободный регистр.
Эта фича называется прееименование регистров, либо как-то так - мне лень гуглить.
Дак вот штука в том, что фича работает через жопу. Мне лень читать мануал и искать почему так, но штука в том, что она ограничивает throughput. На умножении и целочисленном сложении она огранивает throughput c 0.5 до 1.
И вот я решил заюзать сложении через fma:
__v8sf fmaadd(__v8sf a, __v8sf b) {
return _mm256_fmadd_ps(_mm256_set1_ps(1.), a, b);// a + b * 1. == a + b.
}
double memadd_fma(buf_t buf) {
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = {};
do {
summ = fmaadd(summ, *it++);
} while(it != end);
return hsumf(summ);
}
Но меня ждала жопа: 27.347290GB/s, причем не анролл и ничего не помогал. Я уж подумал, что мануал наврал, но позже до меня допёрло: у неё latency 5тактов и ((4.5×8)÷5)×4 ~= 29гигов - т.е. я получаю производительность с её latency, но какой жопой оно так?
Потом я вспомнил, что гцц гинерит анрольный код вида:
add $1, %reg0
add $1, %reg0
//а не
add $1, %reg0
add $1, %reg1
Т.е. на неё вообще не работает переименовывание регистров - и инструкции постоянно в локе. Я это проверил и оказался прав. Ну и я написал такой мемадд:
__v8sf fmaadd(__v8sf a, __v8sf b) {
return _mm256_fmadd_ps(_mm256_set1_ps(1.), a, b);
}
inline void fma_10way_finality(__v8sf * cache, __v8sf * it, __v8sf * end) {
switch(end - it) {
case 8:
*(cache + 7) = fmaadd(*(cache + 7), *(it + 7));
*(cache + 6) = fmaadd(*(cache + 6), *(it + 6));
case 6:
*(cache + 5) = fmaadd(*(cache + 5), *(it + 5));
*(cache + 4) = fmaadd(*(cache + 4), *(it + 4));
case 4:
*(cache + 3) = fmaadd(*(cache + 3), *(it + 3));
*(cache + 2) = fmaadd(*(cache + 2), *(it + 2));
case 2:
*(cache + 1) = fmaadd(*(cache + 1), *(it + 1));
*(cache + 0) = fmaadd(*(cache + 0), *(it + 0));
case 0:
break;
default: error_at_line(-1, 0, __FILE__, __LINE__, "bad_aligned");
}
}
double memaddfma_10way(buf_t buf) {
__v8sf * it = buf_begin(buf), * end = buf_end(buf), summ = (__v8sf){};
__v8sf * cache = (__v8sf[10]){{}};
uint64_t i = 0;
while((it += 10) <= end) {
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
*(cache + i) = fmaadd(*(cache + i), *(it - i - 1));++i;
i = 0;
}
fma_10way_finality(cache, (it - 10), end);
summ = (*(cache + 0) + *(cache + 1) + *(cache + 2) + *(cache + 3) +
*(cache + 4) + *(cache + 5) + *(cache + 6) + *(cache + 7) +
*(cache + 8) + *(cache + 9));
return hsumf(summ);
}
Пришлось хреначить финалити, ибо тут «анролл» на 10, а почему на 10 - для максимального throughput"а - надо, чтобы каждый каждый регистр юзался через 5тактов - т.е. 10регистров.
И вся эта порятнка нужна для борьбы с тупостью конпелятора.
Это уже: 214.167252GB/s(раельно там в районе 250 - просто мой бенч говно). 107 гигафлопс на ведро. Из теоретических 144, но тут уже влияние кеша. Причем 50+ из которых выкидываются и просто бесплатные.
Теперь вопрос к пацанам - что нам дадут эти гагфлопсы, когда у нас будет массив не 32килобайта, а 32мегабайта? Зачем нужно выживать максимум, когда скорость памяти отсилы 20-30гигабайт и нам хватит даже С++ кода с ffast-math?
Ну и призываются упомянутые мною пацаны: mv - этот тот експерт, что вещал про «руками переименовывать регистры не надо» и «анрол ваще ненужен», emulek вещал про ненужность счёта тактов, и не понимал что такое «беслпатно», AIv - не понимал в чем проблема плюсов, ck114 - так же не понимал в чем проблема плюсов.
Бенчи: https://gist.github.com/superhackkiller1997/606be26fa158ef75501d - вроде я там ничего не напутал.
P.S. - не выпиливайте пж, пусть пацаны «нужно» или «не нужно». Мне интеерсно. Ну и там рекомендации пацанов.
Пишу на С++. Нужно ли учить ассемблер? МатЧасть (устройство оперативной памяти, указатели, сколько какая переменная занимает памяти) и так далее примерно знаю (опыт кодинга на с++).
Также очень поверхностно знаю как работает процессор(читал разные статьи на хабре).
Будет ли мне профить от учения ассемблера (Под профитом понимаю лучшее понимание Си-шного кода при роботе с памятью указателями и разные принципы оптимизации)
UPD Мне все равно на мой заработок. Я хочу программировать как бог.
Перемещено mono из talks
Почему-то лисп весьма прочно ассоциируется с сабжем, при этом метапрограммирование тут трактуется весьма однобоко: как генерация программ, их исходников.
Во-первых, любой тьюринг-полный язык может генерировать тексты прог на произвольном языке, лисп тут ортогонален, разве что удобней, но принципиальной разницы нет.
Во-вторых, обычно умалчивается, что метапрограммирование — это не только, и даже не столько генерация, сколько возможности интроспекции, рефлексии и самомодификации/самогенерации в рантайме. А как обстоят дела с этими, наиболее мощными фишками меты, в этих ваших лиспах?
#include <stdio.h>
int main(int argc, char *argv[])
{
float fl;
char *cp = (char*) &fl;
scanf("%f", &fl);
if (argc > 1) {
printf("%f\n", fl);
}
printf("%f\n", *cp);
return 0;
}
$echo 3.14 | ./a.out
0.000000
$echo 3.14 | ./a.out foo
3.140000
3.140000
$
Почему вывод второго printf зависит от вызова первого?
Хотелось бы иметь какую-то штуку для обращения из скриптовых языков, чтобы не тащить при этом компилятор.
Когда-то был qt-c. Потом был cpp-кусок от qtjambi. Вроде тоже помер. Сейчас смотрю, что в PyQt свой мегавелосипед (SIP — интерфейс из питона к C++), PerlQt — закончился в 2003 году, RubyQt — требует развернуть mingw.
Qt теперь снова только для С++ (и Python)?
Закралось подозрение, что эти 2 термина, которые, зачастую употребляются как синонимы, означают, все же, разные вещи.
Концепцию code-as-data, может быть, следует понимать, как то, что код является first-class сущностью, его можно брать в качестве аргумента и возвращать в качестве значения. Таким свойством обладает, например Pico-lisp:
(set 'fu (quote(x) (let (local 1) (+ (eval x) (eval x)))))
(fu 'local) # 2
Может быть следовало бы разделить эти понятия, чтобы не плодить коней в вакууме? И вообще, был бы очень благодарен, если бы кто-нибудь дал четкое и прозрачное объяснение сабжевых терминов.
Просто не мог не запостить. IMHO, лучший референс по хаскелу: http://dev.stephendiehl.com/hask/
Список в конце поста написан Лавсаном 2 года назад. (2011-03-23 19:56:00) (источник)
Надеюсь, автор не подаст жалобу в Роспатент за перепечатку :-)
Кстати, sudo cast lovesan.
Чтобы проверить актуальность вопроса, всю последнюю неделю я долго и нудно использовал этот список в дискуссиях. Чтобы разобрать отдельные пункты отдельно.
Временное резюме: С++ всё еще актуален по историческим причинам. Еще есть мобилки (sudo cast mono), гиперкластеры для шиндовс 3.11 (sudo cast vromanov) и базы данных. Т.к. он актуален, но не предназначен ни для чего (см. выводы в конце списка) новых специалистов по нему должно быть мало. Маленькая конкуренция на огромной области применения — огромное лавэ $$$. Вот это и есть истинная причина использовать кресты — возможность срубить €€€.
Честно говоря, «хитрый план» мне уже очень надоел, поэтому пора открыть карты.
Заодним, крестопоклонники смогут выйти на последний и решительный бой, т.к. сегодня пятница и вечером будет время пообщаться. Поклонникам мамкиного борща тоже наверняка есть что добавить, конструктивно и аргументированно.
Вот этот список:
По причинам 3, 4, 5, 9 и 10 C++ совершенно неприменим для системного и низкоуровневого программирования. А по причинами 1, 2, 5, 6, 7, 8, и, опять же, 9 и 10 - и для прикладного.
У C++ нет области применения.
Выпущен порт языка программирования Shen на Javascript.
Протестировать работу Shen на JS можно тут.
Для освежения памяти:
Shen - это функциональный язык программирования, являющийся продолжением языка Qi II. Имеет опциональную статическую систему типов, основанную на секвенциальном исчислении, и общее направление на логическое программирование.
Важной целью языка является переносимость. Ядро реализовано с использованием всего 45 функций Kernel Lisp (KL), поэтому язык достаточно быстро может быть перенесён на любую платформу.
Предыдущие посты на ЛОРе по теме:
>>> Подробности (google.com)
Вот некоторые интересные ролики от Symbolics конца 80х — начала 90х годов:
http://www.reddit.com/r/lisp/comments/1o20q2/old_marketing_videos_of_symbolic...
У меня есть два типа понтейнера которые принимают по 3 шаблонных параметра
template<class T, class Deferred, class Deadline>
struct prio_container;
template<class T, class Deferred, class Deadline>
struct queue_container;
Deferred и Deadline это плагины, которые расширяют функционал. Все делается без палиморфизма, исключительно на этапе компиляции (статический полиморфизм).
Я хочу абстрагироваться от конкретных реализаций и сделать интерфейс, который бы через указание шаблонных параметров выбирал нужную специализацию. Притом даже сам тип контейнера для пользователя выглядил бы как подключаемый плагин. А так же отвязаться от порядка задания параметром шаблона, и необходимости указывать их все, даже если они не используются. Вот пример того что я пытаюсь сделать.
template<class T,
class Plugin1 = disable_plugin,
class Plugin2 = disable_plugin,
class Plugin3 = disable_plugin>
struct container;
Я смог додуматься только до перечисление всех возможных специализаций. Но это издец как муторно. и если появятся новые плагины то пиши пропало, число комбинаций перевалит за разумный предел.
#include <iostream>
#include <string>
using namespace std;
#define static_type(name) \
static const std::string& type() \
{ \
static std::string type_(name); \
return type_; \
} \
struct prio_plugin;
struct dis_prio_plugin;
struct deferred_plugin
{ static_type("deferred"); };
struct deadline_plugin
{ static_type("deadline"); };
struct disable_plugin
{ static_type("disable"); };
template<class T, class Deferred, class Deadline>
struct prio_container
{
static const std::string& type()
{
static std::string type_("prio_container<" +
Deferred::type() + ", " +
Deadline::type() + ">");
return type_;
}
};
template<class T, class Deferred, class Deadline>
struct queue_container
{
static const std::string& type()
{
static std::string type_("queue_container<" +
Deferred::type() + ", " +
Deadline::type() + ">");
return type_;
}
};
template<class T,
class Plugin1 = disable_plugin,
class Plugin2 = disable_plugin,
class Plugin3 = disable_plugin>
struct container;
template<class T,
class Plugin1,
class Plugin2>
struct container<T, prio_plugin, Plugin1, Plugin2>
{
typedef prio_container<T, Plugin1, Plugin2> type;
};
template<class T, class DisableDeadline>
struct container<T, prio_plugin, deferred_plugin, DisableDeadline>
{
typedef prio_container<T, deferred_plugin, DisableDeadline> type;
};
template<class T, class DisableDeferred>
struct container<T, prio_plugin, deadline_plugin, DisableDeferred>
{
typedef prio_container<T, DisableDeferred, deadline_plugin> type;
};
template<class T>
struct container<T, prio_plugin, deadline_plugin, deferred_plugin>
{
typedef prio_container<T, deferred_plugin, deadline_plugin> type;
};
template<class T>
struct container<T, prio_plugin, deferred_plugin, deadline_plugin>
{
typedef prio_container<T, deferred_plugin, deadline_plugin> type;
};
int main()
{
cout << "Hello World" << endl;
cout << container<int, prio_plugin>::type::type() << std::endl;
cout << container<int, prio_plugin, deadline_plugin>::type::type() << std::endl;
cout << container<int, prio_plugin, deferred_plugin>::type::type() << std::endl;
cout << container<int, prio_plugin, deferred_plugin, deadline_plugin>::type::type() << std::endl;
cout << container<int, prio_plugin, deadline_plugin, deferred_plugin>::type::type() << std::endl;
return 0;
}
prio_container<disable, disable>
prio_container<disable, deadline>
prio_container<deferred, disable>
prio_container<deferred, deadline>
prio_container<deferred, deadline>
| ← назад | следующие → |
{kind=link}