
Simple Viewer GL – лёгкий однооконный просмотрщик изображений.
Многое из того, что раньше делалось на CPU, теперь выполняется на GPU.
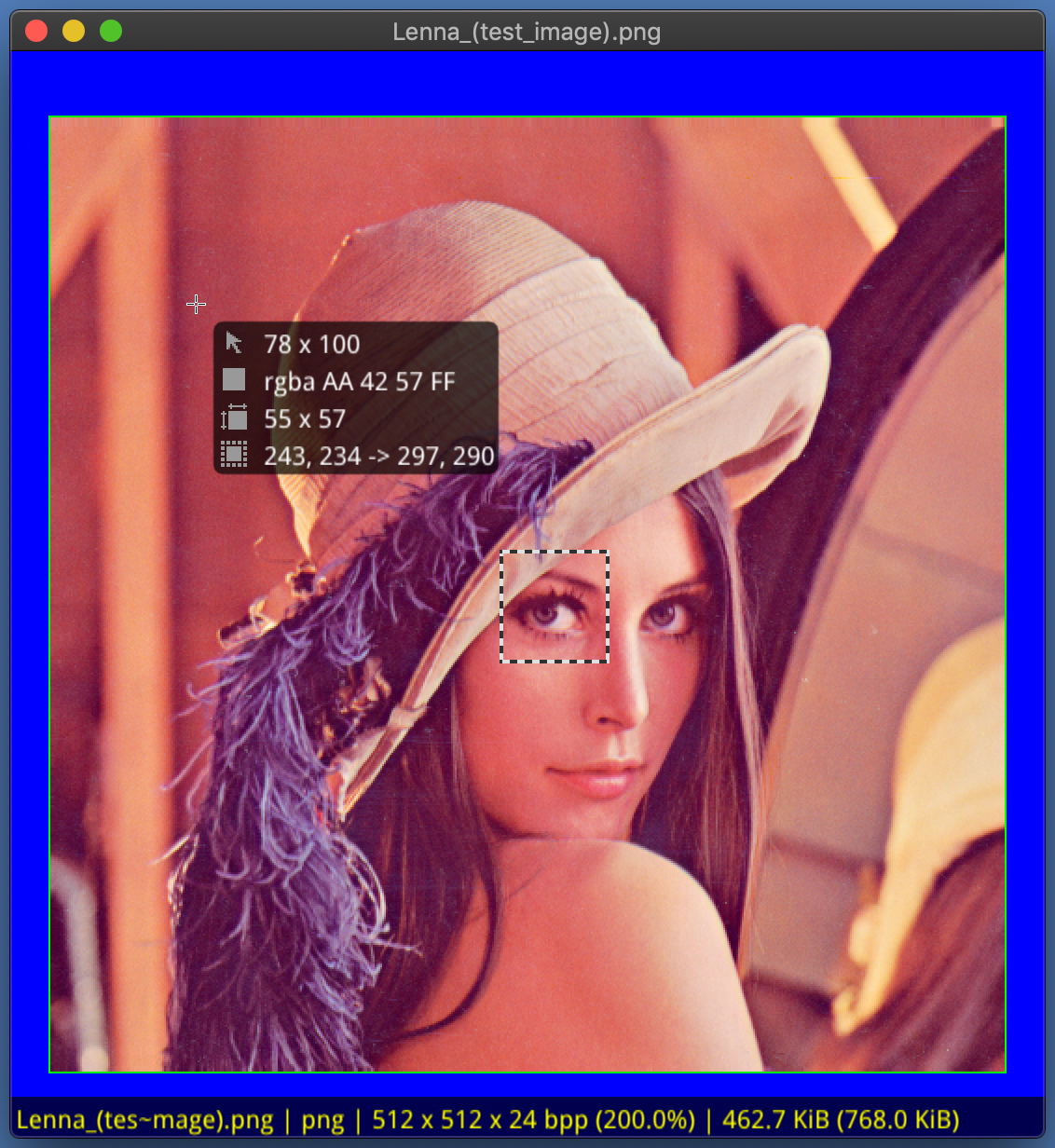
В строке статуса, которую можно отключать клавишей i, отображается базовая информация: формат, разрешение, размер в памяти (CPU + GPU), размер на диске. В режиме информации о пикселе, который включается клавишей p, отображается бабл с информацией о позиции, цвете пикселя, параметрах выделенной области.
Simple Viewer GL умеет определять тип файла по его сигнатуре (параметр -a), а не только по расширению файла. Поддерживается рекурсивный обход директории (параметр -r).
Есть возможность менять в рантайме тип фона (три базовых цвета + шахматная доска) окна или задавать кастомный цвет, что удобно при просмотре изображений с прозрачными пикселями.
Поддерживаемые форматы:
- PNG
- JPEG
- JPEG 2000
- HEIF
- PSD (Adobe Photoshop)
- AI (Adobe Illustrator)
- EPS
- XCF (GIMP)
- GIF
- SVG
- TIFF
- TARGA
- ICO
- ICNS (Apple Icon Image)
- BMP
- PNM
- DDS
- XWD
- SCR (ZX-Spectrum screen)
- XPM
- WebP
- OpenEXR
Поддерживаются GNU/Linux, FreeBSD и macOS. Существует сторонний форк для Windows.
Новое в Simple Viewer GL 3.3.1:
- переработана архитектура вьювера;
- а потому и новый чуть более гибкий рендерер;
- благодаря рендереру профили и прочие преобразования перенёс с CPU на GPU;
- благодаря переработанной архитектуре починил и загрузку, и прогресс (спиннер);
- значительно снизился расход памяти. Теперь память по возможности выделяется только под несколько чанков. Нет полной распакованной копии изображения в памяти;
- информация о пикселе тянется из видеокарты;
- счётчик расхода памяти учитывает видеопамять;
- добавил превью для форматов которые его поддерживают. Если есть превью в EXIF, то беру из него;
- переработал интерфейс. Переделал рендерер, обновил и ImGui из ветки с поддержкой докинга окон;
- новый попап EXIF в доке справа, а в него добавил категории и поиск;
- переработал панель статуса. Просто сделал удобнее её внутри, а заодно поправил визуал;
- теперь панель статуса не перекрывает изображение. И вообще, любое закреплённое у края окно не перекрывает изображение;
- расширил поддержку PSD. Теперь поддерживаются практически все вариации;
- добавил поддержку HEIF (AVIF/HEIC);
- починил greyscale jpeg2k – теперь яркость корректная;
- добавил поддержку цветовых профилей там, где их не было, но формат их поддерживал;
- и ещё кучу того, что и вспомнить не могу, а логи читайте сами, мне лень.
Наверняка что-нибудь отломал, поэтому буду рад замечаниям и советам.
Лицензия GPL-2.0.







