Группа разработчиков обещает создать расширение RISC-V для работы с графикой. Анонс упоминает троих:
- Атиф Зафар (Atif Zafar), директор компании Pixilica, выпускающей Arduino-совместимые платы FPGA для разработчиков RISC-V.
- Грант Дженнингс (Grant Jennings), директор по международному маркетингу GOWIN Semiconductor, выпускающей неколько семейств FPGA (в том числе DSP и микроконтроллеры) и инструментарий для дизайна.
- Тед Мэрина (Ted Marena), старший директор экосистемы RISC-V в Western Digital и временный директор CHIPS Alliance, разработчика и хостера проектов открытого аппаратного обеспечения.
План предусматривает:
- Завершить разработку набора векторных команд «V».
- Создать на его базе набор 32-битных инструкций «X» (RV32X) — для обработки изображений и 3-мерной графики, и с добавлением новых типов данных для графики.
- Выпустить эталонную реализацию RV32X (в FPGA).
- Масштабировать RV32X в 64 бита — RV64X.
Заявленные цели включают:
- Экономное использование площади чипа.
- Отсутствие конкуренции с коммерческими предложениями.
- Ориентация на FPGA, ASIC, микроконтроллеры с низким энергопотреблением.
- Соответствие DirectX Shader Model 5, OpenGL/ES и Vulkan.
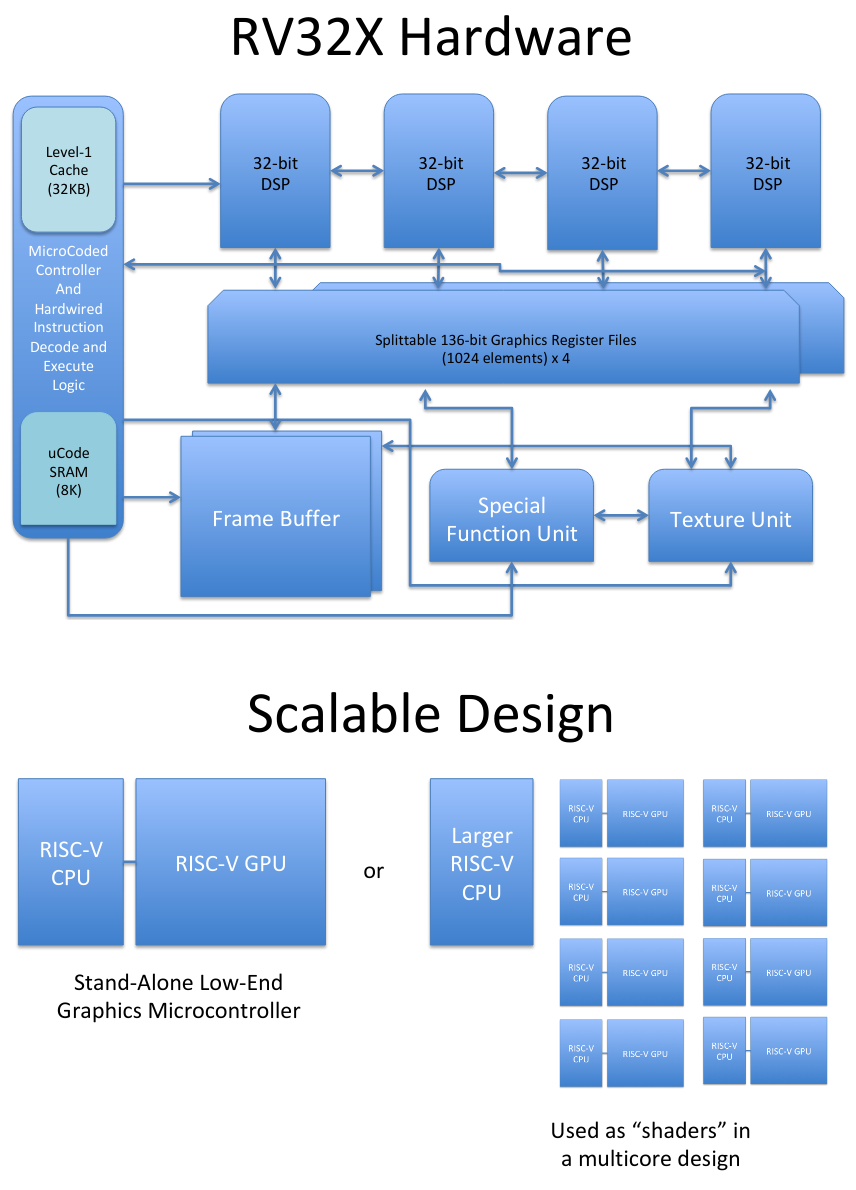
Как видно из рисунка, возможны будут и маломощный процессор RISC-V с единственным графическим блоком, и использование множества таких процессоров в качестве шейдеров большого GPU параллельно с основным процессором RISC-V.
Согласно статье в EE Times будут использованы некоторые идеи Libre GPU.


