https://www.infowatch.ru/analytics/utechki-informatsii/krazha-konfidentsialnoy-informatsii-iz-tsentra-superkompyuterov
https://www.gazeta.ru/tech/news/2026/04/08/28229191.shtml
https://substackcdn.com/image/fetch/$s_!LwlW!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb4a18e63-ccb6-4e02-9b19-7f9a031b805e_1424x746.jpeg
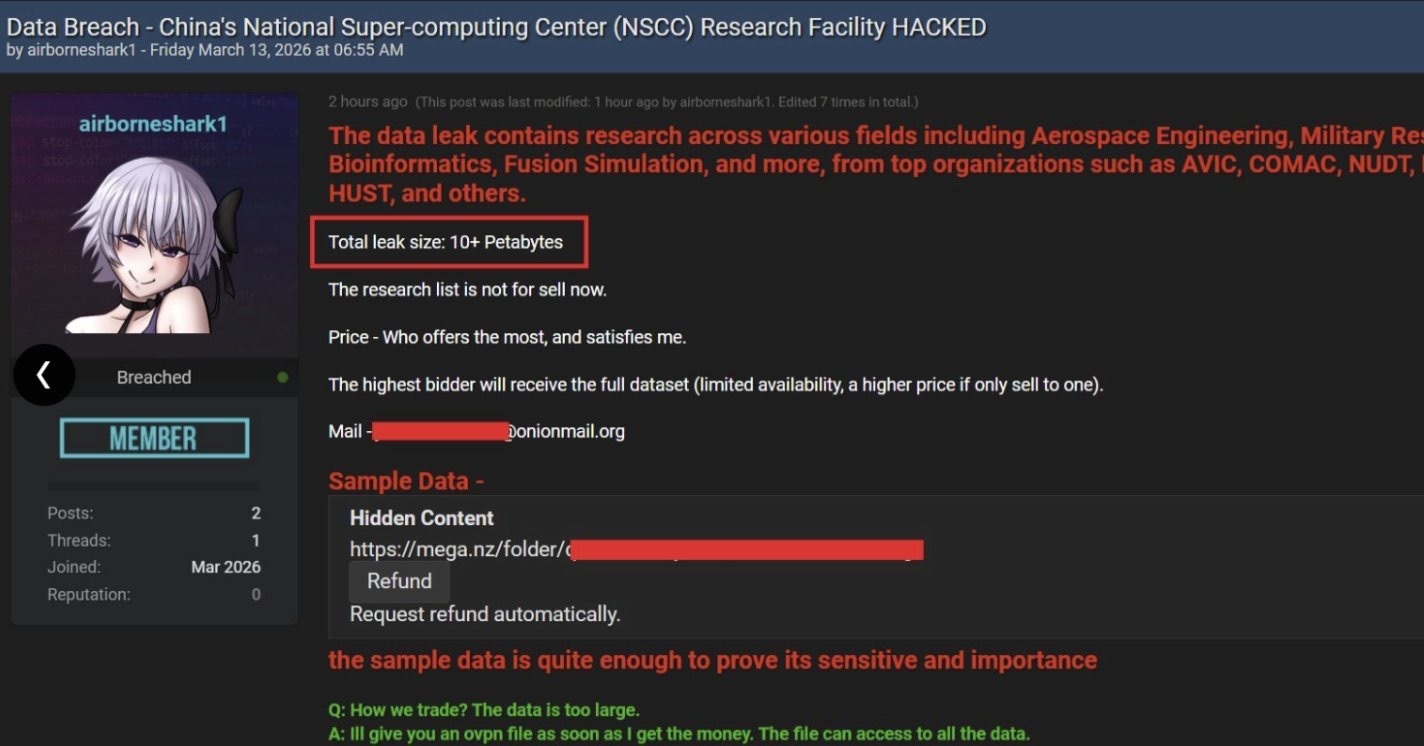
Неизвестный, пишущий по-английски с ошибками, утверждает, что влез в Национальный Центр Суперкомпьютеров Китая (в Тянцзине) через дырявый VPN и за полгода скачал 10 петабайт данных. Говорит, что там — секретные результаты моделирования пробития бронированных целей, ядерного синтеза, что-то аэрокосмическое и биоинформационное, и т.п. Выставил на продажу в середине марта. За просмотр оглавления берёт 10 монеро (~$3000).
И я подумал: если моделировать сплавы клеточными автоматами, каждое зерно 25 мкм³ сделать отдельным автоматом, выделить на него 1 байт, то для моделирования столкновения танка (10 м³ стали) со стеной понадобится 10/(25e-18)=4e17 байт для каждого состояния. То есть 400 петабайт.
Каковы типичные объёмы данных при моделировании сплошных сред на суперкомпьютерах?












{kind=link}