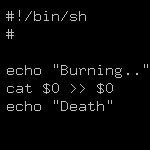
Пишу на языке давно и успешно, отношусь к нему сугубо положительно, но есть конечно моменты, которые, мягко говоря не устраивают.
Итак, претензии к Perl от человека, который его осилил и знает особенности языка не по наслышке:
1) Не хватает собственно скорости. Скорость исполнения кода, т.е. его непосредственной интерпретации - Ахиллесова пята не только Perl, но и Ruby, и Python, и PHP. Но если интерпретаторы PHP и Python становятся быстрее с каждым годом, то интерпретатор Perl застрял в своём развитии - и при этом язык не имеет LLVM-компиляторов, как тот же Crystal, реализующий очень быстрый диалект Ruby. Для Perl есть RPerl, который непонятно как работает и работает ли у кого-то, кроме самого Вина Бразвелла. Ну и да, RPerl - это всё-таки не вполне Perl, по сути это какой-то «perl'оподобный диалект языка Си»
2) Не хватает адекватной проверки входных параметров. Есть куча сторонних модулей для этого: MooseX::Method::Signatures, Params::Validate и ещё тысячи их, но все они добавляют дикий оверхед к и без того не быстрой работе интерпретатора
3) Отсутствует как класс нормальный параллелизм: без пула потоков работать с потоками невозможно (создание потока - крайне медленная операция), с пулом потоков в принципе удобно, но всё одно памяти они жрут как не в себя. На Perl в 100 раз всё лучше с процессами, в том числе есть неплохие модули для работы с shared memory (правда, Redis для того же самого намного удобнее).
4) CPAN конечно замечательный репозиторий пакетов, но выкладывать что-то туда - это лишняя трата времени, да и все эти инструкции по правильному выкладыванию немного бесят: мне что, заняться больше нечем? ИМХО подход того же Crystal'а с его shards'ами намного удобнее.
5) Отсутствие макрогенерации кода. Есть конечно eval, но это, мягко говоря, всё равно что бульдозером шпалы укладывать: неудобно, анахронично, работает в рантайме (что просто ппц на самом деле), чревато ошибками. Учитывая стоимость вызова процедур в Perl5 отсутствие макрогенерации негативно влияет на потенциальную производительность
Относительно удобства ООП претензий не имею - те, у кого они есть, просто пришли из других языков и пытаются применять к совершенно иначе устроенному Perl'у свои «обобщённые» знания.