Данная статья не стремится к научной полноте и не содержит формул, однако включает ссылки на исследования, которые были использованы при её подготовке. Статья призвана познакомить читателя с тем, как биологические механизмы могут применяться при разработке искусственных нейронных сетей для создания сильного искусственного интеллекта (AGI).
В прошлых статьях [1 (linux.org.ru)],[2 (linux.org.ru)] мы рассмотрели сложную структуру нейронной сети в виде кортикальных колонок со спайковой передачей сигнала. Пришло время изменить подход к самим вычислениям, чтобы выйти за пределы кремниевой логики.
Мы привыкли думать, что искусственный интеллект — это бесконечное умножение матриц. Миллиарды параметров, гигаватты энергии и детерминированная логика. Но если мы хотим приблизиться к природе настоящего мышления, нам придётся признать: мозг — это не калькулятор. И если мы хотим, чтобы наша сеть перестала быть калькулятором, нам придётся попробовать шаг в сторону — туда, где вычисление становится не только числом, но и событием. Для этого мы реализуем одну из самых дерзких теорий сознания XX века — теорию Orch-OR Роджера Пенроуза и Стюарта Хамероффа в виде квантового вычислителя в Readout-слое.
Теория Orchestrated Objective Reduction (Orch-OR) — это популярная (и спорная) идея о том, что сознание может быть связано с квантовыми процессами внутри нейронов (микротрубочки Пенроуза), а не только с электрическими сигналами между ними. Микротрубочки находятся внутри нейрона в длинных отростках:
- в дендритах — ветвистые «антенны», принимающие сигнал
- в аксоне — длинный «провод», по которому уходит сигнал
Трубочки состоят из белка тубулина, который собирается в цепочки, а цепочки складываются в полую трубку. Физик (и математик) Пенроуз выдвинул гипотезу о том, что тубулин, который может находиться в разных состояниях, образует квантовые суперпозиции [3 (sciencedirect.com)]. В отличие от классической квантовой механики в гипотезе Пенроуза наблюдатель не нужен — суперпозиции не могут существовать бесконечно, так как они сами по себе нестабильны. Коллапс происходит объективно: не потому, что произошло наблюдение, а потому что происходит сам по себе, имеет физическую причину (гравитация) и определённое время существования [4 (frontiersin.org)].
Хамерофф — анестезиолог, заинтересовался тем, что анестезия очень надёжно «выключает» сознание, но не обязательно полностью выключает мозг. Под анестезией мозг продолжает иметь активность, но исчезает связное субъективное переживание. Он предположил, что анестетики действуют не только на синапсы, но и на более фундаментальный механизм, который «собирает сознание». Теория Orch-OR говорит, что анестетики нарушают квантовую когерентность тубулина [5 (oup.com)]. В тубулине есть «карманы» (участки белка), куда могут садиться маленькие молекулы. Многие анестетики — маленькие, жирорастворимые молекулы. Если анестетик садится в тубулин, то он меняет колебания, конформации и разрушает условия для квантовой когерентности. Если когерентность разрушена — сознание выключается [6 (sciencedirect.com)].
Это неподтверждённая, но очень интересная теория, отлично подходящая как пример использования квантовых вычислений в кортикально-спайковых нейронных сетях. Во всем мире опубликовано не больше 5 подобных работ. Давайте исправим это, потому что — можем.
Ввиду отсутствия под рукой криостата с абсолютным нулем, квантовых вычислителей и нейроморфных спайковых процессоров, мы упростим многие детали, оставив базу, достаточную для наглядности и воспроизводимости широким кругом читателей.
Для этого нам понадобится установить открытую программную платформу для разработки и запуска гибридных квантово-классических приложений Nvidia CudaQ. Она позволяет объединить работу традиционных графических процессоров (GPU) и центральных процессоров (CPU) с квантовыми процессорами (QPU) в едином рабочем процессе. Установка сводится к выполнению команды pip install cudaq. В статье используется версия 0.12, но представленный ниже код будет работать и на соседних версиях. Также нам понадобится видеокарта Nvidia архитектуры Turing, Ampere, Ada, Hopper или Blackwell (те 20XX и новее) и примерно 24 Gb оперативной памяти на одну эпоху обучения так как обучение гибридной сети будет идти одновременно и на GPU, и на CPU вместе с квантовой GPU-симуляцией.
Создадим файл brain_quantum.py и импортируем используемые пакеты:
#!/usr/bin/env python3
import gc
import torch
from torch import nn
import torch.nn.functional as F
import networkx as nx
import math
import numpy as np
import cudaq
Квантового вычислительного модуля (QPU) у нас нет, поэтому переключим cudaq в режим работы на видеокарте:
cudaq.set_target("nvidia")
Для квантовых вычислений нам необходимо создать квантовое ядро — минимальную схему, которая будет превращать обычный вектор чисел в квантовое состояние. Не в «результат измерения», не в битовую строку, а именно в состояние: в чистую волну вероятностей, которая ещё не сделала выбор. Это принципиально важно: пока мы не измеряем, квантовая система остаётся не ответом, а возможностью.
Создадим регистр из n_qubits кубитов (в нашем случае 10). В терминах квантовой механики он стартует в базовом состоянии: ∣0000000000⟩
Это чистая точка отсчёта. Никакой информации, никакой структуры, никакой памяти — только нулевая конфигурация. Почти как мозг до первого сенсорного импульса. Теперь вводим данные. Но делаем это не через запись числа в ячейку, как в классическом компьютере. Мы делаем более странную вещь: поворачиваем состояние кубита на сфере Блоха.
Гейт RY(θ) — это вращение вокруг оси Y. И каждый угол angles[i] становится не числом в памяти, а физическим преобразованием состояния. В результате каждый кубит перестаёт быть строго 0 или 1, а входной вектор превращается в «вектор возможностей». Не значением, а вероятность стать значением.
У нас получился набор независимых кубитов, каждый со своей суперпозицией. Это всё ещё параллельные независимые параметры. Поэтому следующий шаг — связать кубиты так, чтобы система стала неразделимой. Для этого используем гейт CNOT (условное изменение): один кубит становится управляющим, другой — управляемым. Циклически свяжем наши кубиты с помощью этого гейта. После применения CNOT между соседями квантовое состояние перестаёт быть произведением отдельных кубитов. Оно становится общим объектом:
- состояние одного кубита больше нельзя описать без остальных
- информация начинает существовать не в узлах, а в связях
Важный момент: на этом этапе мы перестаём моделировать «множество независимых мыслей» и начинаем моделировать «единое переживание», где всё зависит от всего.
Цепочка — это хорошо, но она имеет края. А края — это место, где структура ломается. Поэтому мы замыкаем её в кольцо: последний кубит влияет на первый. Так мы создаём периодическую топологию: нет начала и нет конца. Это маленькая модель системы, где корреляции могут циркулировать, а не упираться в границы.
И… всё. Здесь скрыта главная «метафизика» этого ядра: мы не делаем измерения.
Это значит, что схема не производит классический результат. Она оставляет систему в состоянии, которое ещё не схлопнулось. И именно поэтому CUDA-Q может вернуть полный вектор состояний в виде структуры амплитуд для обучения сети.
Соберем всё, описанное выше, в квантовое ядро:
"""
Квантовое ядро для создания запутанного состояния:
1. Инициализирует кубиты в состоянии |000...0⟩
2. Применяет RY вращения для кодирования входных данных
3. Создаёт запутанность через CNOT gates в кольцевой топологии, где:
angles: список углов для RY вращений [n_qubits элементов]
n_qubits: количество кубитов
Важно: это ядро НЕ делает измерения, поэтому мы можем получить полный вектор состояний.
"""
@cudaq.kernel
def prepare_entangled_state(angles: list[float], n_qubits: int):
# Создаём регистр кубитов
q = cudaq.qvector(n_qubits)
# Шаг 1: Кодирование данных через RY вращения
# RY gate вращает состояние кубита вокруг оси Y на блоховой сфере
for i in range(n_qubits):
ry(angles[i], q[i])
# Шаг 2: Создание квантовой запутанности (линейная цепочка)
# CNOT gates создают корреляции между соседними кубитами
# После этого система становится неразделимой — состояние одного кубита зависит от состояния других кубитов
for i in range(n_qubits - 1):
cx(q[i], q[i+1])
# Шаг 3: Замыкание цепочки в кольцо: последний кубит связывается с первым
# Это создаёт периодическую граничную топологию
cx(q[n_qubits-1], q[0])
# Шаг 4: ВАЖНО: мы НЕ делаем измерения здесь! Это позволяет CUDA-Q вернуть полный вектор состояний
Мы спроектировали квантовое ядро, которое:
- Преобразует входящий список углов
anglesв квантовое состояние черезry - С помощью
cx(CNOT) создаёт запутанность в виде цепочки связанных кубитов - С помощью
cx(CNOT) создаёт запутанность последнего кубита с первым, создавая кольцо кубитов - Отсутствие измерения сохраняет «волну возможностей» - амплитуд в виде вектора состояний.
Это ядро не для «вычисления ответа», это квантовый образ входа — запутанный, целостный, не сведённый к отдельным компонентам.
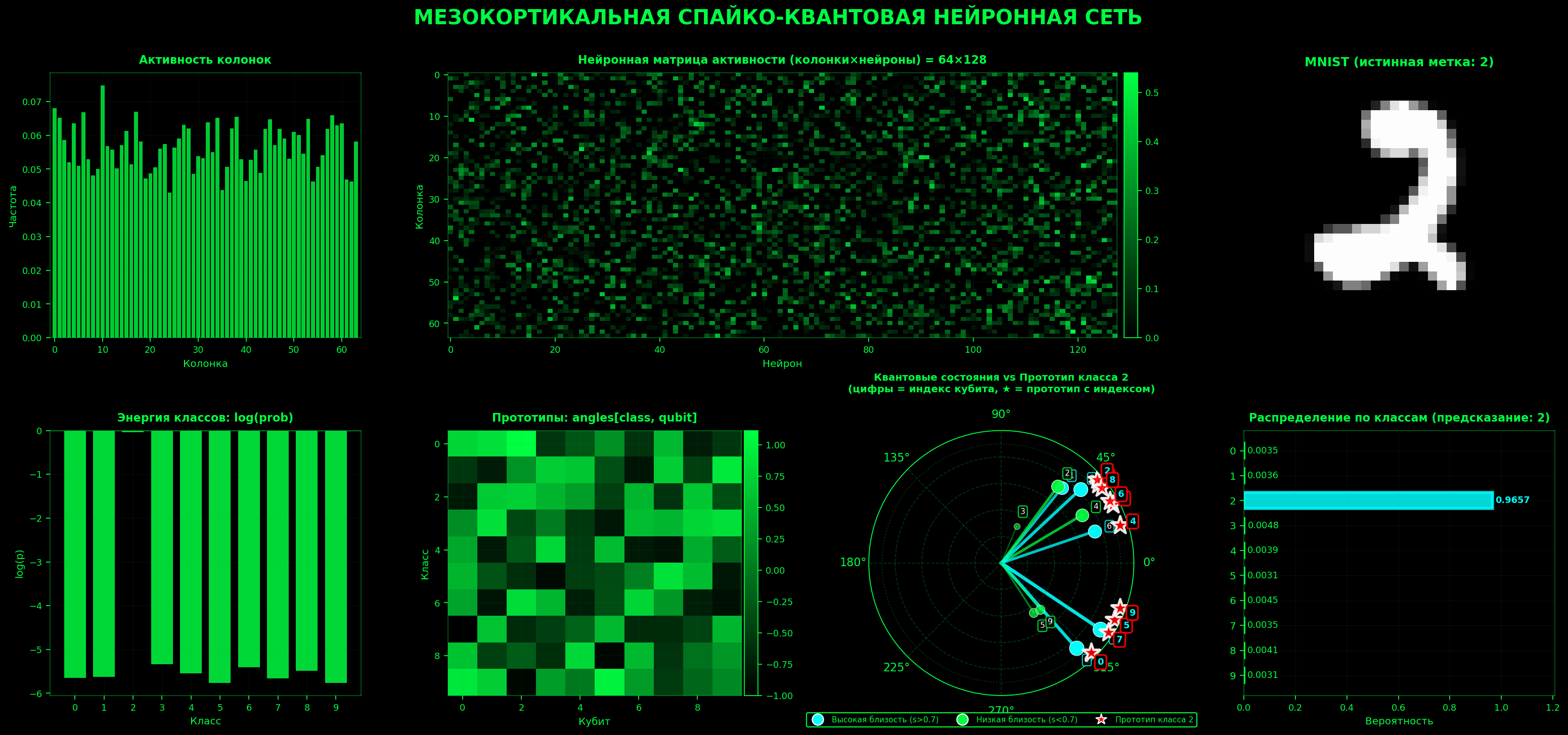
Теперь нам нужно заменить классический readout из предыдущей статьи на квантовый. Такой readout должен уметь слушать спайковый кортекс из 64 мезокортикальных колонок и отвечать на вопрос: к какому классу MNIST этот паттерн ближе в квантовом пространстве? Но не как обычный числовой классификатор, а как резонанс между входным состоянием и набором квантовых «ментальных образов» — прототипов.
Главная идея этой архитектуры — прототипы как квантовые архетипы.
prototypes — это обучаемые параметры формы [C, Q], где C — число классов, а Q — число кубитов. Это не веса нейронов в привычном смысле. Это квантовые эталоны: идеальные состояния, соответствующие образам цифр.
Реализуем эту архитектуру поэтапно:
-
Сначала мы должны преобразовать входные спайки: нормировать их, затем сжать, и превратить в набор углов
angles. Эти углы кодируют каждый пример батча как квантовую конфигурацию через вращенияry(см. квантовое ядро). В итоге каждый вход становится набором параметровθ— углами физических вращений на сфере Блоха, то есть буквально инструкцией: как повернуть кубиты, чтобы получить состояние, соответствующее этому паттерну активности колонок. -
Все квантовые вычисления происходят внутри прокси-класса
QReadoutFn. Мы берём два семейства состояний: входные (angles) и прототипные (prototypes), строим их вектора состояний (вот здесь, в квантовом компьютере, было бы измерение) и сравниваем по мере «квантовой близости»", то есть по силе перекрытия двух волновых функций. Дальше мы превращаем эту близость в логиты, умножая её наtemperature: так мы регулируем резкость распределения — степень «уверенности» системы. Результат возвращается в виде тензора и уходит в обычныйsoftmax. -
Классического градиента для квантовой схемы у нас нет, поэтому мы используем метод
parameter-shift: для каждого параметра делаются два прогона схемы (θ+shiftиθ−shift), а производная вычисляется как разность между ними.
В итоге мы получаем почти идеальную амплитудную картину квантового состояния без статистического шума измерений, но расплачиваемся за это экспоненциально растущим по Q размером вектора состояний и тяжёлыми вычислениями. Настоящие квантовые компьютеры избавлены от симуляторной экспоненты, но квантовая природа процесса и там, и тут остаётся одной и той же.
Ниже приведён код, реализующий все описанные шаги: от компрессии спайкового вектора в углы до квантового сравнения с прототипами и обучения через parameter-shift:
"""
Дифференцируемый квантовый readout через parameter-shift.
"""
class QuantumPrototypeReadout(nn.Module):
def __init__(self, in_dim, num_classes=10, n_qubits=10):
super().__init__()
self.in_dim = in_dim
self.num_classes = num_classes
self.n_qubits = n_qubits
# Шаг 1: Подготовка входа: нормируем и сжимаем выход 64 мезокортикальных колонок в Q углов (по одному на кубит), которые станут "инструкцией" для вращений RY на сфере Блоха
self.norm = nn.LayerNorm(in_dim)
self.compress = nn.Sequential(
nn.Linear(in_dim, 64),
nn.GELU(),
nn.Linear(64, n_qubits),
nn.Tanh()
)
# Квантовые прототипы-архетипы классов: [C, Q] — для каждого класса свой набор углов
self.prototypes = nn.Parameter(torch.randn(num_classes, n_qubits) * 0.05)
# Температура управляет резкостью логитов (уверенностью softmax)
self.temperature = nn.Parameter(torch.tensor(5.0))
class _QReadoutFn(torch.autograd.Function):
@staticmethod
def forward(ctx, angles, prototypes, temperature, n_qubits):
# Шаг 2: превращаем angles и prototypes в квантовые состояния и сравниваем их по fidelity (квантовой близости / резонансу)
device = angles.device
angles_np = angles.detach().cpu().numpy().copy()
protos_np = prototypes.detach().cpu().numpy().copy()
B, Q = angles_np.shape
C = protos_np.shape[0]
# Строим state-vector для каждого входного примера
input_states = []
for b in range(B):
state = cudaq.get_state(prepare_entangled_state, angles_np[b].tolist(), n_qubits)
input_states.append(np.array(state))
input_states = np.stack(input_states, axis=0)
# Строим state-vector для каждого прототипа класса
proto_states = []
for c in range(C):
state = cudaq.get_state(prepare_entangled_state, protos_np[c].tolist(), n_qubits)
proto_states.append(np.array(state))
proto_states = np.stack(proto_states, axis=0)
fidelities = np.zeros((B, C), dtype=np.float64)
for b in range(B):
for c in range(C):
ov = np.vdot(proto_states[c], input_states[b])
fidelities[b, c] = np.abs(ov) ** 2
# Логиты = температура * близость
temp_val = float(temperature.detach().cpu().item())
logits = fidelities * temp_val
# Сохраняем данные для backward (parameter-shift)
ctx.n_qubits = n_qubits
ctx.shift = math.pi / 2.0
ctx.device = device
ctx.save_for_backward(torch.tensor(angles_np), torch.tensor(protos_np), torch.tensor(fidelities), temperature)
del input_states
del proto_states
del angles_np
del protos_np
gc.collect()
return torch.from_numpy(logits).to(device).float()
@staticmethod
def backward(ctx, grad_output):
# Шаг 3: обучение без классического градиента, используем parameter-shift: для каждого параметра делаем два прогона схемы (θ+π/2 и θ-π/2) и берём разность, получая точную производную для RY
angles_t, protos_t, fidelities_t, temperature = ctx.saved_tensors
angles_np = angles_t.numpy()
protos_np = protos_t.numpy()
fidelities = fidelities_t.numpy()
temp_val = float(temperature.detach().cpu().item())
shift = ctx.shift
n_qubits = ctx.n_qubits
device = ctx.device
B, Q = angles_np.shape
C = protos_np.shape[0]
grad_output_np = grad_output.detach().cpu().numpy()
grad_angles = np.zeros_like(angles_np, dtype=np.float64)
grad_protos = np.zeros_like(protos_np, dtype=np.float64)
grad_temp = float((grad_output_np * fidelities).sum())
proto_states = []
for c in range(C):
state = cudaq.get_state(prepare_entangled_state, protos_np[c].tolist(), n_qubits)
proto_states.append(np.array(state))
proto_states = np.stack(proto_states, axis=0)
for b in range(B):
for q in range(Q):
angles_plus = angles_np.copy()
angles_minus = angles_np.copy()
angles_plus[b, q] += shift
angles_minus[b, q] -= shift
psi_plus = np.array(cudaq.get_state(prepare_entangled_state, angles_plus[b].tolist(), n_qubits))
psi_minus = np.array(cudaq.get_state(prepare_entangled_state, angles_minus[b].tolist(), n_qubits))
F_plus = np.zeros(C, dtype=np.float64)
F_minus = np.zeros(C, dtype=np.float64)
for c in range(C):
ovp = np.vdot(proto_states[c], psi_plus)
ovm = np.vdot(proto_states[c], psi_minus)
F_plus[c] = np.abs(ovp) ** 2
F_minus[c] = np.abs(ovm) ** 2
dF = (F_plus - F_minus) / 2.0
dlogits = temp_val * dF
grad_angles[b, q] = float((grad_output_np[b, :] * dlogits).sum())
del psi_plus, psi_minus
del F_plus, F_minus
if (b % 8) == 0:
gc.collect()
del proto_states
input_states_back = []
for b in range(B):
input_states_back.append(
np.array(cudaq.get_state(prepare_entangled_state, angles_np[b].tolist(), n_qubits))
)
input_states_back = np.stack(input_states_back, axis=0)
for c in range(C):
for q in range(Q):
protos_plus = protos_np.copy()
protos_minus = protos_np.copy()
protos_plus[c, q] += shift
protos_minus[c, q] -= shift
psi_proto_plus = np.array(cudaq.get_state(prepare_entangled_state, protos_plus[c].tolist(), n_qubits))
psi_proto_minus = np.array(cudaq.get_state(prepare_entangled_state, protos_minus[c].tolist(), n_qubits))
F_plus = np.zeros(B, dtype=np.float64)
F_minus = np.zeros(B, dtype=np.float64)
for b in range(B):
ovp = np.vdot(psi_proto_plus, input_states_back[b])
ovm = np.vdot(psi_proto_minus, input_states_back[b])
F_plus[b] = np.abs(ovp) ** 2
F_minus[b] = np.abs(ovm) ** 2
dF = (F_plus - F_minus) / 2.0
grad_protos[c, q] = float((grad_output_np[:, c] * (temp_val * dF)).sum())
del psi_proto_plus, psi_proto_minus
del F_plus, F_minus
if (c % 4) == 0:
gc.collect()
del input_states_back
grad_angles_t = torch.from_numpy(grad_angles).to(device=device, dtype=torch.float32)
grad_protos_t = torch.from_numpy(grad_protos).to(device=device, dtype=torch.float32)
grad_temp_t = torch.tensor(grad_temp, device=device, dtype=temperature.dtype)
del grad_angles
del grad_protos
del grad_temp
gc.collect()
return grad_angles_t, grad_protos_t, grad_temp_t, None
def forward(self, x, y=None):
# Преобразуем спайковый паттерн в углы для кубитов, x — это выход спайкового кортекса: агрегированный вектор признаков из 64 мезокортикальных колонок.
norm_x = self.norm(x)
angles = self.compress(norm_x) * math.pi
# Сравниваем входное квантовое состояние с прототипами классов
logits = self._QReadoutFn.apply(angles, self.prototypes, self.temperature, self.n_qubits)
# Финальный классический softmax (как обычно)
probs = F.softmax(logits, dim=1)
return probs, angles
Квантовая часть нашей сети готова. Её работу можно представить так: 64 колонки — это хор. Каждая колонка поёт свой мотив (спайки). QuantumPrototypeReadout превращает мотивы в звуковые волны на новой частоте (преобразует углы в квантовое состояние) и сопоставляет их с эталонными мелодиями (прототипами). Fidelity (резонанс) — это не просто «насколько похожи ноты», это «насколько волны интерферируют и резонируют». Обучение подстраивает эталонные мелодии и способ трансформации входа так, чтобы хор и архетипы созвучали — и тогда MNIST-цифра «вспыхивает» в виде уверенной вероятности на выходе softmax.
Осталось встроить это в нашу мезокортикальную сеть из прошлой статьи [2 (linux.org.ru)], заменив классический self.readout на новый квантовый вариант. Поскольку архитектура сети уже была подробно разобрана ранее, ниже приведём её код с минимальными изменениями — только теми, которые необходимы для интеграции квантовой части:
def make_small_world(num_nodes: int, k: int = 8, p: float = 0.15) -> torch.Tensor:
G = nx.watts_strogatz_graph(num_nodes, k, p)
adj = torch.zeros(num_nodes, num_nodes)
for i, j in G.edges():
adj[i, j] = adj[j, i] = 1.0
return adj
class LIFNeuron(nn.Module):
def __init__(self, tau_mem=20.0, tau_syn=5.0, threshold=2.0):
super().__init__()
self.threshold = threshold
self.register_buffer('alpha', torch.tensor(math.exp(-1.0 / tau_mem)))
self.register_buffer('beta', torch.tensor(math.exp(-1.0 / tau_syn)))
def forward(self, input_current, mem, syn):
syn = self.beta * syn + input_current
mem = self.alpha * mem + syn
spike = (mem >= self.threshold).float()
mem = mem * (1.0 - spike)
return spike, mem, syn
class SpikeColumn(nn.Module):
def __init__(self, in_feat, out_feat, e_i_ratio=0.8):
super().__init__()
self.n_exc = int(out_feat * e_i_ratio)
self.n_inh = out_feat - self.n_exc
self.fc_exc = nn.Linear(in_feat, self.n_exc, bias=False)
self.fc_inh = nn.Linear(in_feat, self.n_inh, bias=False)
self.lif_exc = LIFNeuron(threshold=2.5)
self.lif_inh = LIFNeuron(threshold=2.0)
nn.init.kaiming_normal_(self.fc_exc.weight)
nn.init.kaiming_normal_(self.fc_inh.weight)
with torch.no_grad():
self.fc_exc.weight *= 0.3
self.fc_inh.weight *= -0.3
def init_state(self, batch_size, device):
return {
'm_e': torch.zeros(batch_size, self.n_exc, device=device),
's_e': torch.zeros(batch_size, self.n_exc, device=device),
'm_i': torch.zeros(batch_size, self.n_inh, device=device),
's_i': torch.zeros(batch_size, self.n_inh, device=device)
}
def forward(self, x, st):
sp_e, m_e, s_e = self.lif_exc(self.fc_exc(x), st['m_e'], st['s_e'])
sp_i, m_i, s_i = self.lif_inh(self.fc_inh(x), st['m_i'], st['s_i'])
return torch.cat([sp_e, -sp_i], dim=1), {'m_e': m_e, 's_e': s_e, 'm_i': m_i, 's_i': s_i}
class STDP(nn.Module):
def __init__(self, num_columns, formation_thr=0.8, pruning_thr=0.05, max_density=0.25):
super().__init__()
self.num_columns = num_columns
self.formation_threshold = formation_thr
self.pruning_threshold = pruning_thr
self.max_density = max_density
self.register_buffer('decay', torch.tensor(math.exp(-1.0 / 20.0)))
self.register_buffer('connection_potential', torch.zeros(num_columns, num_columns))
self.register_buffer('connection_usage', torch.zeros(num_columns, num_columns))
def update_metrics(self, pre, post, adj, weights):
with torch.no_grad():
pre_d = pre.detach()
post_d = post.detach()
self.connection_potential.data.mul_(0.99).add_(0.01 * torch.ger(post_d, pre_d))
usage = adj * weights.detach().abs()
self.connection_usage.data.mul_(0.95).add_(0.05 * usage)
class DynamicTopologyNetwork(nn.Module):
def __init__(self, num_columns=64, in_dim=784, col_out=128, time_steps=50):
super().__init__()
self.num_columns = num_columns
self.time_steps = time_steps
self.input_scale = nn.Parameter(torch.ones(in_dim) * 0.5)
self.columns = nn.ModuleList([SpikeColumn(in_dim, col_out) for _ in range(num_columns)])
self.topology = nn.Parameter(make_small_world(num_columns), requires_grad=False)
self.inter_weights = nn.Parameter(torch.randn(num_columns, num_columns) * 0.1)
self.stdp = STDP(num_columns)
# Квантовый readout через CUDA-Q
self.readout = QuantumPrototypeReadout(in_dim=num_columns)
self.register_buffer('training_step', torch.tensor(0))
def _poisson_encode(self, x):
x_scaled = (x * self.input_scale.unsqueeze(0)).clamp(0.0, 1.0)
return (torch.rand_like(x_scaled) < x_scaled).float()
def _update_topology(self):
with torch.no_grad():
density = self.topology.sum() / (self.num_columns**2)
if density < self.stdp.max_density:
can_form = (self.topology == 0) & (self.stdp.connection_potential > self.stdp.formation_threshold)
if can_form.any():
self.topology.data[can_form] = 1.0
to_prune = (
(self.topology > 0) &
(self.stdp.connection_usage < self.stdp.pruning_threshold) &
(self.inter_weights.abs() < 0.05)
)
self.topology.data[to_prune] = 0.0
self.inter_weights.data[to_prune] = 0.0
def forward(self, x, y=None):
batch_size, device = x.shape[0], x.device
states = [col.init_state(batch_size, device) for col in self.columns]
spike_acc = torch.zeros(batch_size, self.num_columns, device=device)
inter_conn = torch.sigmoid(self.inter_weights) * self.topology
for t in range(self.time_steps):
in_spikes = self._poisson_encode(x)
curr_cols = []
for i, col in enumerate(self.columns):
s, new_state = col(in_spikes, states[i])
states[i] = {k: v.detach() for k, v in new_state.items()}
curr_cols.append(s.abs().mean(1))
step_spikes = torch.stack(curr_cols, dim=1)
influence = torch.matmul(step_spikes, inter_conn.t())
spike_acc += step_spikes * (1.0 + 0.1 * influence)
if self.training:
self.stdp.update_metrics(
step_spikes.mean(0),
step_spikes.mean(0),
self.topology,
self.inter_weights
)
if self.training:
self.training_step += 1
if self.training_step % 100 == 0:
self._update_topology()
col_features = spike_acc / self.time_steps
return self.readout(col_features, y), col_features.mean(0)
Прежде чем попробовать сеть в работе, нужно оценить вычислительную сложность:
- Forward делает
~B + Cвызововcudaq.get_state - Backward (parameter-shift) делает примерно
2 * B * Qвызовов для градиентов по входным углам и2 * C * Qдля прототипов (плюс предвычисленныеBвходных состояний). Итого — сотни/тысячи симуляций на шаге обратного прохода при типичныхB, Q, C
Каждая симуляция оперирует вектором состояний длиной 2 в степени Q (кубитов). Для Q = 10 это 1024 комплексных амплитуды, что вполне приемлемо для обычного оборудования; для Q ≈ 20 уже практически нереально. Для 50 кубитов нам бы уже не хватило памяти всей планеты, поэтому ограничимся 10 кубитами.
Давайте проверим получившуюся сеть, создадим файл train_quantum.py и обучим сеть. Код обучения тривиальный потому ограничимся комментариями в коде:
#!/usr/bin/env python3
import gc
import os
import glob
import torch
import time
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from brain_quantum import DynamicTopologyNetwork
batch_size = 32 # размер батча для обучения
epochs = 10 # количество полных проходов по датасету
learning_rate = 1e-3 # скорость обучения для градиентного спуска
weight_decay = 1e-4 # L2-регуляризация для предотвращения переобучения
label_smoothing = 0.1 # предотвращает рост temperature и снижает дисперсию loss
checkpoint_dir = 'checkpoints' # директория для сохранения модели
def train():
os.makedirs(checkpoint_dir, exist_ok=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
model = DynamicTopologyNetwork(num_columns=64, in_dim=784, col_out=128, time_steps=50).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
start_epoch = 1
checkpoint_files = glob.glob(os.path.join(checkpoint_dir, "checkpoint_epoch_*.pt"))
if checkpoint_files:
latest_checkpoint = max(checkpoint_files, key=lambda x: int(x.split('_')[-1].split('.')[0]))
checkpoint = torch.load(latest_checkpoint, map_location=device)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])
scheduler.eta_min = 1e-5
start_epoch = checkpoint['epoch'] + 1
print(f"Обучение возобновлено с эпохи {start_epoch}")
else:
print("Чекпоинты не найдены. Начинаем обучение с нуля")
for epoch in range(start_epoch, epochs + 1):
model.train()
running_loss = 0.0
correct = 0
total = 0
start_time = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
(probs, q_angles), rates = model(data, target)
log_probs = torch.log(probs + 1e-9)
nll = F.nll_loss(log_probs, target)
smooth_loss = -log_probs.mean()
loss = (1.0 - label_smoothing) * nll + label_smoothing * smooth_loss
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=0.5)
optimizer.step()
if batch_idx % 100 == 0:
gc.collect()
running_loss += loss.item()
pred = probs.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.size(0)
if batch_idx % 10 == 0:
curr_acc = 100. * correct / total
print(f'Эпоха: {epoch:02d} [{batch_idx*len(data):5d}/{len(train_loader.dataset)}] Лосс: {loss.item():.4f} Точность: {curr_acc:.2f}%')
test_acc = evaluate(model, test_loader, device)
epoch_time = time.time() - start_time
print(f"\nЭпоха {epoch} завершена. Точнсть: {test_acc:.2f}% Время эпохи: {epoch_time:.2f}s")
checkpoint_path = os.path.join(checkpoint_dir, f"checkpoint_epoch_{epoch}.pt")
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'test_acc': test_acc
}, checkpoint_path)
print(f"Чекпоинт сохранен: {checkpoint_path}")
scheduler.step()
final_path = os.path.join(checkpoint_dir, "quantum_brain.pt")
torch.save({
'epoch': epochs,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
}, final_path)
print("\nОбучение завершено. Финальная модель сохранена как 'quantum_brain.pt'")
def evaluate(model, loader, device):
model.eval()
correct = 0
with torch.no_grad():
for data, target in loader:
data, target = data.to(device), target.to(device)
(probs, q_angles), rates = model(data, target)
pred = probs.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
return 100. * correct / len(loader.dataset)
if __name__ == "__main__":
train()
Частые переносы данных между GPU и CPU создают очень много временных данных которые к концу батча могут занимать 20-24 Gb оперативной памяти. Если у вас меньше 256 Gb оперативной памяти рекомендуется останавливать обучение после каждой эпохи и запускать заново, обучающий скрипт сам продолжит обучение с нужной эпохи.
Запускаем обучение: ./train_quantum.py. Ниже приведен пример первой эпохи обучения:
Чекпоинты не найдены. Начинаем обучение с нуля
Эпоха: 01 [ 0/60000] Лосс: 2.3071 Точность: 9.38%
Эпоха: 01 [ 320/60000] Лосс: 2.2722 Точность: 12.22%
Эпоха: 01 [ 640/60000] Лосс: 2.2315 Точность: 15.92%
Эпоха: 01 [ 960/60000] Лосс: 2.1937 Точность: 22.98%
Эпоха: 01 [ 1280/60000] Лосс: 2.1806 Точность: 28.81%
Эпоха: 01 [ 1600/60000] Лосс: 2.1385 Точность: 32.97%
Эпоха: 01 [ 1920/60000] Лосс: 2.0448 Точность: 37.30%
Эпоха: 01 [ 2240/60000] Лосс: 2.0615 Точность: 40.76%
Эпоха: 01 [ 2560/60000] Лосс: 2.0117 Точность: 43.63%
Эпоха: 01 [ 2880/60000] Лосс: 1.9612 Точность: 46.33%
Эпоха: 01 [ 3200/60000] Лосс: 1.8916 Точность: 49.26%
Эпоха: 01 [ 3520/60000] Лосс: 1.8944 Точность: 51.38%
Эпоха: 01 [ 3840/60000] Лосс: 1.9539 Точность: 53.05%
Эпоха: 01 [ 4160/60000] Лосс: 1.7713 Точность: 54.79%
Эпоха: 01 [ 4480/60000] Лосс: 1.7131 Точность: 56.38%
Эпоха: 01 [ 4800/60000] Лосс: 1.7863 Точность: 57.64%
Эпоха: 01 [ 5120/60000] Лосс: 1.6615 Точность: 58.73%
Эпоха: 01 [ 5440/60000] Лосс: 1.6927 Точность: 59.61%
Эпоха: 01 [ 5760/60000] Лосс: 1.6370 Точность: 60.62%
Эпоха: 01 [ 6080/60000] Лосс: 1.6155 Точность: 61.65%
Эпоха: 01 [ 6400/60000] Лосс: 1.5447 Точность: 62.34%
Эпоха: 01 [ 6720/60000] Лосс: 1.6180 Точность: 62.97%
Эпоха: 01 [ 7040/60000] Лосс: 1.4954 Точность: 63.73%
Эпоха: 01 [ 7360/60000] Лосс: 1.4000 Точность: 64.52%
Эпоха: 01 [ 7680/60000] Лосс: 1.4466 Точность: 65.15%
Эпоха: 01 [ 8000/60000] Лосс: 1.4839 Точность: 65.86%
Эпоха: 01 [ 8320/60000] Лосс: 1.3785 Точность: 66.44%
Эпоха: 01 [ 8640/60000] Лосс: 1.2770 Точность: 66.94%
Эпоха: 01 [ 8960/60000] Лосс: 1.2862 Точность: 67.44%
Эпоха: 01 [ 9280/60000] Лосс: 1.3269 Точность: 67.91%
Эпоха: 01 [ 9600/60000] Лосс: 1.1473 Точность: 68.45%
Эпоха: 01 [ 9920/60000] Лосс: 1.4780 Точность: 68.81%
Эпоха: 01 [10240/60000] Лосс: 1.2396 Точность: 69.14%
Эпоха: 01 [10560/60000] Лосс: 1.1494 Точность: 69.50%
Эпоха: 01 [10880/60000] Лосс: 1.2106 Точность: 69.83%
Эпоха: 01 [11200/60000] Лосс: 1.1730 Точность: 70.20%
Эпоха: 01 [11520/60000] Лосс: 1.2437 Точность: 70.39%
Эпоха: 01 [11840/60000] Лосс: 1.1602 Точность: 70.66%
Эпоха: 01 [12160/60000] Лосс: 1.1444 Точность: 70.98%
Эпоха: 01 [12480/60000] Лосс: 0.8871 Точность: 71.31%
Эпоха: 01 [12800/60000] Лосс: 1.0406 Точность: 71.61%
Эпоха: 01 [13120/60000] Лосс: 1.0027 Точность: 71.88%
Эпоха: 01 [13440/60000] Лосс: 1.1937 Точность: 72.08%
Эпоха: 01 [13760/60000] Лосс: 1.1134 Точность: 72.36%
Эпоха: 01 [14080/60000] Лосс: 1.0241 Точность: 72.56%
Эпоха: 01 [14400/60000] Лосс: 0.9040 Точность: 72.80%
Эпоха: 01 [14720/60000] Лосс: 0.8479 Точность: 73.05%
Эпоха: 01 [15040/60000] Лосс: 0.9612 Точность: 73.26%
Эпоха: 01 [15360/60000] Лосс: 0.9122 Точность: 73.47%
Эпоха: 01 [15680/60000] Лосс: 0.8325 Точность: 73.68%
Эпоха: 01 [16000/60000] Лосс: 0.9514 Точность: 73.90%
Эпоха: 01 [16320/60000] Лосс: 0.9759 Точность: 74.07%
Эпоха: 01 [16640/60000] Лосс: 0.8976 Точность: 74.26%
Эпоха: 01 [16960/60000] Лосс: 0.9059 Точность: 74.46%
Эпоха: 01 [17280/60000] Лосс: 0.8197 Точность: 74.69%
Эпоха: 01 [17600/60000] Лосс: 0.9561 Точность: 74.91%
Эпоха: 01 [17920/60000] Лосс: 0.8704 Точность: 75.06%
Эпоха: 01 [18240/60000] Лосс: 0.7022 Точность: 75.19%
Эпоха: 01 [18560/60000] Лосс: 0.8722 Точность: 75.40%
Эпоха: 01 [18880/60000] Лосс: 0.7988 Точность: 75.53%
Эпоха: 01 [19200/60000] Лосс: 0.6883 Точность: 75.71%
Эпоха: 01 [19520/60000] Лосс: 0.7017 Точность: 75.88%
Эпоха: 01 [19840/60000] Лосс: 0.7743 Точность: 76.03%
Эпоха: 01 [20160/60000] Лосс: 0.6906 Точность: 76.17%
Эпоха: 01 [20480/60000] Лосс: 0.7100 Точность: 76.37%
Эпоха: 01 [20800/60000] Лосс: 0.9196 Точность: 76.45%
Эпоха: 01 [21120/60000] Лосс: 0.7301 Точность: 76.60%
Эпоха: 01 [21440/60000] Лосс: 0.7475 Точность: 76.71%
Эпоха: 01 [21760/60000] Лосс: 0.8210 Точность: 76.82%
Эпоха: 01 [22080/60000] Лосс: 0.6518 Точность: 76.94%
Эпоха: 01 [22400/60000] Лосс: 0.8392 Точность: 77.06%
Эпоха: 01 [22720/60000] Лосс: 0.8009 Точность: 77.15%
Эпоха: 01 [23040/60000] Лосс: 0.8899 Точность: 77.23%
Эпоха: 01 [23360/60000] Лосс: 0.8482 Точность: 77.32%
Эпоха: 01 [23680/60000] Лосс: 0.6401 Точность: 77.42%
Эпоха: 01 [24000/60000] Лосс: 0.7867 Точность: 77.55%
Эпоха: 01 [24320/60000] Лосс: 0.5907 Точность: 77.69%
Эпоха: 01 [24640/60000] Лосс: 0.6156 Точность: 77.82%
Эпоха: 01 [24960/60000] Лосс: 0.7120 Точность: 77.92%
Эпоха: 01 [25280/60000] Лосс: 0.6652 Точность: 78.01%
Эпоха: 01 [25600/60000] Лосс: 0.6651 Точность: 78.09%
Эпоха: 01 [25920/60000] Лосс: 0.6757 Точность: 78.20%
Эпоха: 01 [26240/60000] Лосс: 0.6532 Точность: 78.28%
Эпоха: 01 [26560/60000] Лосс: 0.6224 Точность: 78.38%
Эпоха: 01 [26880/60000] Лосс: 0.8578 Точность: 78.43%
Эпоха: 01 [27200/60000] Лосс: 0.7904 Точность: 78.50%
Эпоха: 01 [27520/60000] Лосс: 0.7040 Точность: 78.55%
Эпоха: 01 [27840/60000] Лосс: 0.5190 Точность: 78.66%
Эпоха: 01 [28160/60000] Лосс: 0.7131 Точность: 78.76%
Эпоха: 01 [28480/60000] Лосс: 0.6409 Точность: 78.83%
Эпоха: 01 [28800/60000] Лосс: 0.6543 Точность: 78.90%
Эпоха: 01 [29120/60000] Лосс: 0.7505 Точность: 78.96%
Эпоха: 01 [29440/60000] Лосс: 0.4579 Точность: 79.01%
Эпоха: 01 [29760/60000] Лосс: 0.6109 Точность: 79.11%
Эпоха: 01 [30080/60000] Лосс: 0.5557 Точность: 79.19%
Эпоха: 01 [30400/60000] Лосс: 0.6470 Точность: 79.24%
Эпоха: 01 [30720/60000] Лосс: 0.6576 Точность: 79.32%
Эпоха: 01 [31040/60000] Лосс: 0.6528 Точность: 79.41%
Эпоха: 01 [31360/60000] Лосс: 0.5032 Точность: 79.51%
Эпоха: 01 [31680/60000] Лосс: 0.7932 Точность: 79.58%
Эпоха: 01 [32000/60000] Лосс: 0.5078 Точность: 79.68%
Эпоха: 01 [32320/60000] Лосс: 0.5797 Точность: 79.78%
Эпоха: 01 [32640/60000] Лосс: 0.4630 Точность: 79.86%
Эпоха: 01 [32960/60000] Лосс: 0.5738 Точность: 79.95%
Эпоха: 01 [33280/60000] Лосс: 0.4593 Точность: 80.02%
Эпоха: 01 [33600/60000] Лосс: 0.6020 Точность: 80.10%
Эпоха: 01 [33920/60000] Лосс: 0.4380 Точность: 80.17%
Эпоха: 01 [34240/60000] Лосс: 0.5299 Точность: 80.27%
Эпоха: 01 [34560/60000] Лосс: 0.6248 Точность: 80.35%
Эпоха: 01 [34880/60000] Лосс: 0.5963 Точность: 80.43%
Эпоха: 01 [35200/60000] Лосс: 0.8581 Точность: 80.46%
Эпоха: 01 [35520/60000] Лосс: 0.5494 Точность: 80.49%
Эпоха: 01 [35840/60000] Лосс: 0.6003 Точность: 80.52%
Эпоха: 01 [36160/60000] Лосс: 0.8301 Точность: 80.57%
Эпоха: 01 [36480/60000] Лосс: 0.4872 Точность: 80.63%
Эпоха: 01 [36800/60000] Лосс: 0.6245 Точность: 80.70%
Эпоха: 01 [37120/60000] Лосс: 0.4560 Точность: 80.80%
Эпоха: 01 [37440/60000] Лосс: 0.7116 Точность: 80.87%
Эпоха: 01 [37760/60000] Лосс: 0.4338 Точность: 80.93%
Эпоха: 01 [38080/60000] Лосс: 0.6776 Точность: 80.98%
Эпоха: 01 [38400/60000] Лосс: 0.5273 Точность: 81.02%
Эпоха: 01 [38720/60000] Лосс: 0.7700 Точность: 81.04%
Эпоха: 01 [39040/60000] Лосс: 0.5480 Точность: 81.09%
Эпоха: 01 [39360/60000] Лосс: 0.4222 Точность: 81.14%
Эпоха: 01 [39680/60000] Лосс: 0.5785 Точность: 81.21%
Эпоха: 01 [40000/60000] Лосс: 0.5651 Точность: 81.28%
Эпоха: 01 [40320/60000] Лосс: 0.6876 Точность: 81.33%
Эпоха: 01 [40640/60000] Лосс: 0.4776 Точность: 81.36%
Эпоха: 01 [40960/60000] Лосс: 0.5436 Точность: 81.40%
Эпоха: 01 [41280/60000] Лосс: 0.6431 Точность: 81.44%
Эпоха: 01 [41600/60000] Лосс: 0.4239 Точность: 81.50%
Эпоха: 01 [41920/60000] Лосс: 0.6738 Точность: 81.53%
Эпоха: 01 [42240/60000] Лосс: 0.5285 Точность: 81.60%
Эпоха: 01 [42560/60000] Лосс: 0.4785 Точность: 81.65%
Эпоха: 01 [42880/60000] Лосс: 0.6261 Точность: 81.68%
Эпоха: 01 [43200/60000] Лосс: 0.4249 Точность: 81.74%
Эпоха: 01 [43520/60000] Лосс: 0.7252 Точность: 81.81%
Эпоха: 01 [43840/60000] Лосс: 0.5580 Точность: 81.86%
Эпоха: 01 [44160/60000] Лосс: 0.6108 Точность: 81.88%
Эпоха: 01 [44480/60000] Лосс: 0.5022 Точность: 81.95%
Эпоха: 01 [44800/60000] Лосс: 0.3176 Точность: 81.99%
Эпоха: 01 [45120/60000] Лосс: 0.8446 Точность: 82.03%
Эпоха: 01 [45440/60000] Лосс: 0.3811 Точность: 82.06%
Эпоха: 01 [45760/60000] Лосс: 0.6208 Точность: 82.08%
Эпоха: 01 [46080/60000] Лосс: 0.5078 Точность: 82.10%
Эпоха: 01 [46400/60000] Лосс: 0.4753 Точность: 82.15%
Эпоха: 01 [46720/60000] Лосс: 0.4872 Точность: 82.20%
Эпоха: 01 [47040/60000] Лосс: 0.3935 Точность: 82.26%
Эпоха: 01 [47360/60000] Лосс: 0.4829 Точность: 82.31%
Эпоха: 01 [47680/60000] Лосс: 0.4163 Точность: 82.34%
Эпоха: 01 [48000/60000] Лосс: 0.5871 Точность: 82.37%
Эпоха: 01 [48320/60000] Лосс: 0.4647 Точность: 82.41%
Эпоха: 01 [48640/60000] Лосс: 0.5003 Точность: 82.44%
Эпоха: 01 [48960/60000] Лосс: 0.3379 Точность: 82.50%
Эпоха: 01 [49280/60000] Лосс: 0.4031 Точность: 82.53%
Эпоха: 01 [49600/60000] Лосс: 0.3451 Точность: 82.57%
Эпоха: 01 [49920/60000] Лосс: 0.4187 Точность: 82.61%
Эпоха: 01 [50240/60000] Лосс: 0.4981 Точность: 82.63%
Эпоха: 01 [50560/60000] Лосс: 0.5509 Точность: 82.66%
Эпоха: 01 [50880/60000] Лосс: 0.4453 Точность: 82.70%
Эпоха: 01 [51200/60000] Лосс: 0.4752 Точность: 82.74%
Эпоха: 01 [51520/60000] Лосс: 0.4432 Точность: 82.76%
Эпоха: 01 [51840/60000] Лосс: 0.7082 Точность: 82.79%
Эпоха: 01 [52160/60000] Лосс: 0.2837 Точность: 82.82%
Эпоха: 01 [52480/60000] Лосс: 0.3412 Точность: 82.85%
Эпоха: 01 [52800/60000] Лосс: 0.6121 Точность: 82.87%
Эпоха: 01 [53120/60000] Лосс: 0.4517 Точность: 82.90%
Эпоха: 01 [53440/60000] Лосс: 0.3764 Точность: 82.93%
Эпоха: 01 [53760/60000] Лосс: 0.1879 Точность: 82.97%
Эпоха: 01 [54080/60000] Лосс: 0.3549 Точность: 83.00%
Эпоха: 01 [54400/60000] Лосс: 0.3967 Точность: 83.04%
Эпоха: 01 [54720/60000] Лосс: 0.4770 Точность: 83.08%
Эпоха: 01 [55040/60000] Лосс: 0.3702 Точность: 83.11%
Эпоха: 01 [55360/60000] Лосс: 0.4863 Точность: 83.14%
Эпоха: 01 [55680/60000] Лосс: 0.5427 Точность: 83.19%
Эпоха: 01 [56000/60000] Лосс: 0.5258 Точность: 83.23%
Эпоха: 01 [56320/60000] Лосс: 0.7753 Точность: 83.23%
Эпоха: 01 [56640/60000] Лосс: 0.5694 Точность: 83.25%
Эпоха: 01 [56960/60000] Лосс: 0.2631 Точность: 83.26%
Эпоха: 01 [57280/60000] Лосс: 0.6100 Точность: 83.30%
Эпоха: 01 [57600/60000] Лосс: 0.4950 Точность: 83.33%
Эпоха: 01 [57920/60000] Лосс: 0.3806 Точность: 83.35%
Эпоха: 01 [58240/60000] Лосс: 0.4866 Точность: 83.38%
Эпоха: 01 [58560/60000] Лосс: 0.2366 Точность: 83.40%
Эпоха: 01 [58880/60000] Лосс: 0.3163 Точность: 83.44%
Эпоха: 01 [59200/60000] Лосс: 0.4950 Точность: 83.48%
Эпоха: 01 [59520/60000] Лосс: 0.3646 Точность: 83.52%
Эпоха: 01 [59840/60000] Лосс: 0.2980 Точность: 83.54%
Эпоха 1 завершена. Точность: 89.81% Время эпохи: 4961.57s
...
Не удивляйтесь, если точность на проверке оказывается выше, чем на обучении — это нормально для подобных гибридных сетей. Итоговая точность после всех эпох также может колебаться в пределах примерно 92–96%, что тоже естественно — ведь, как и в биологических мозгах, встречаются экземпляры поумнее и попроще.
Мы получили жизнеспособную мезокортикальную спайко-квантовую нейронную сеть. Настоящий гибрид класса «Больной Ублюдок», где традиционным является разве что входной слой данных. Пройдемся по её основным характеристикам:
В основе структуры сети лежит не статический граф, а динамическая, «дышащая» структура. Классические нейросети смотрят на мир застывшими кадрами. Наша SNN-часть (Spiking Neural Network) воспринимает мир во времени:
- Спайки вместо чисел: Информация кодируется не амплитудой, а моментом времени. Это язык, на котором общаются реальные нейроны.
- Динамическая топология: Мы отказались от полносвязных слоев. Используя принципы STDP (Spike-Timing-Dependent Plasticity), сеть сама решает, какие связи усилить, а какие — физически разорвать. Из тысяч возможных соединений остаются лишь сотня-другая самых важных.
- Эффект «Малого Мира»: Топология сети самоорганизуется в граф, где локальные группы нейронов связаны плотно, а далёкие отделы соединены слабо.
Здесь нет глобального учителя. Кортекс учится на локальных правилах, создавая «сырые» смыслы из шума входящих данных. Это наше подсознание, живущее во времени.
Другая половина нашей сети — квантовая. Это не просто эмуляция «в стиле квантов». Это математически строгая симуляция квантовой механики. Давайте ещё раз проследим путь данных от нейрона к кубиту.
Представьте, что SNN обработала изображение цифры и выдала 64 числа — это усредненная активность кортикальных колонок. Напрямую подать их в квантовый компьютер нельзя. Сначала происходит сжатие: нейросеть проецирует эти 64 признака в 10 углов вращения (по одному на каждый кубит). Мы больше не работаем с яркостью пикселей, мы работаем с фазами.
Здесь начинается квантовая физика. Каждый из 10 углов подается на гейт вращения RY. В этот момент кубит перестает быть битом (0 или 1). Он переходит в состояние суперпозиции: кубит находится одновременно во всех состояниях с определенной вероятностью.
Если бы мы остановились на суперпозиции, это было бы просто 10 вероятностных монеток. Но мы идем дальше. Модель применяет CNOT-гейты (controlled-NOT), связывая кубиты в кольцевую топологию: первый запутывается со вторым, второй с третьим… и десятый замыкается на первый.
После этого состояние системы становится неразделимым. Его невозможно описать как «состояние первого кубита + состояние второго». Теперь существует только единая волновая функция всей системы. Один спайк на входе больше не влияет на один кубит — он меняет глобальный узор интерференции. Вместо 10 чисел мы теперь работаем с вектором из 1024 комплексных амплитуд (2 в 10 степени). Это то самое экспоненциальное расширение пространства признаков, ради которого создаются квантовые компьютеры.
Как же сеть понимает, что она видит?
У неё есть 10 прототипов (для цифр 0–9). Каждый прототип — это тоже сложное запутанное квантовое состояние. Классификация происходит через вычисление Quantum Fidelity — меры близости двух квантовых состояний. Грубо говоря, мы берём скалярное произведение двух 1024-мерных комплексных векторов. Тот прототип, с которым у входного образа возникает максимальный «резонанс» (fidelity), и считается правильным ответом.
Для обучения (настройки углов) используется техника Parameter-Shift. Чтобы узнать, куда крутить кубит для улучшения результата, модель создает две параллельные реальности: в одной угол сдвинут на +π/2, а другой на -π/2. Разница в fidelity между этими реальностями даёт нам точный градиент. Для одного батча из 32 картинок мы проводим сотни таких симуляций!
Эта работа показывает, что будущее AI, возможно, лежит не в триллионах параметров трансформеров, а в качественном усложнении самой парадигмы вычислений.
Мы создали модель, где:
- Память — это интерференционная картина.
- Обучение — это настройка резонанса через parameter-shift.
- Распознавание — это коллапс неопределённости.
Это шаг от искусственного интеллекта, который считает, к искусственной интуиции, которая наблюдает. Если микротрубочки Пенроуза действительно работают так, как мы моделируем, то мы только что сделали маленький шаг к пониманию физики мысли.
Послесловие
Через два месяца (в апреле 2026 года) на конференции TSC 2026 доктор Сатору Ватанабэ планировал представить экспериментальные данные, указывающие на нелокальную корреляцию между сигналами ЭЭГ и квантовыми состояниями. Его работа предлагает новую модель «наблюдателя», в которой субъективный опыт трактуется как точка пересечения биологической активности и квантовых процессов в микротрубочках, тем самым развивая идеи Пенроуза о невычислимости сознания. Автор утверждает, что исследование эмпирически выявляет корреляции между ЭЭГ-активностью участников и состояниями квантового процессора, удалённого от них почти на 8000 километров [7 (researchgate.net)].
Но этого не произойдет, конференция отменена, по неподтверждённой информации она организовывалась фондом Джеффри Эпштейна…
References:
- Obezyan et al., Нейронные сети нетрадиционной ориентации, LOR (2026)
- Obezyan et al., Нейронные сети нетрадиционного возбуждения, LOR (2026)
- Escola-Gascon et al., Evidence of quantum-entangled higher states of consciousness, Sciencedirect (2025)
- Sergi A. et al., The quantum-classical complexity of consciousness and orchestrated objective reduction, Frontiersin (2025)
- Wiest M. et al., A quantum microtubule substrate of consciousness is experimentally supported and solves the binding and epiphenomenalism problems, Neuroscience of Consciousness (2025)
- Wiest M. et al., Conscious active inference II: Quantum orchestrated objective reduction among intraneuronal microtubules naturally accounts for discrete perceptual cycles, Sciencedirect (2025)
- Satoru Watanabe at., Empirical Subjectivity Intersection:Observer–Quantum Coherence Beyond ExistingTheories Unifying Relativity, Quantum Mechanics, and Cosmology, Researchgate (2025)