Данная статья не стремится к научной полноте и не содержит формул и графиков, однако включает ссылки на исследования, которые были использованы при её подготовке. Статья призвана познакомить читателя с тем, как биологические механизмы могут применяться при разработке искусственных нейронных сетей для создания сильного искусственного интеллекта (AGI).
Для оправдания кликбейтного заголовка давайте сначала кратко рассмотрим традиционные нейронные сети. Их можно классифицировать по топологии следующим образом:
- Топологически сложные — биологические мозги
- Топологически простые — искуственные нейронные сети (от простых сверточных сетей до Transformers и Mamba архитектур)
Каждый тип обладает своими преимуществами и недостатками.
Биологические мозги обладают самосознанием, опытом, внутренней памятью и картиной мира, но обучение занимает годы, удержание изученного материала ограничено, а вычислительные возможности сравнительно малы.
Искусственные сети обучаются быстро, способны оперировать большим контекстом и эффективно аппроксимируют задачи, но полностью отсутствует самосознание и понимание того, что они делают.
Очевидно, что для создания AGI требуется объединить преимущества обоих типов нейронных сетей. В данной статье будет рассмотрен именно такой подход: создание нетрадиционной сети, которая сочетает достоинства биологических и искусственных систем. Некоторые детали намеренно упрощены, но при этом эффективность метода не страдает, что позволяет читателю воспроизвести его на современных процессорах или видеокартах, выпущенных за последнее десятилетие.
Для демонстрации будем использовать язык, позволяющий экспериментировать не приходя в сознание: Python (v3.10.14). В качестве фреймворка для гибкой работы с нейронными сетями выберем torch (v2.8.0), а для построения графов - networkx (v3.3). Точные версии не обязательны: представленный код будет работать и на соседних версиях этих библиотек.
В качестве эталона будем использовать распознавание цифр из датасета MNIST. Датасет содержит 70000 размеченных изображений цифр (0‑9) в оттенках серого, размером 28х28 px, общий объём примерно 12МБ.
Простые топологии искусственных нейронных сетей показывают точность от 80% до 98%. Специализированные сети, «заточенные» под задачу, достигают 99+% [1 (arxiv.org)].
Сложная топология (человеческий мозг) в среднем демонстрирует точность ~99.5‑99.7% (данные приблизительные, поскольку детальные исследования на людях пока что проведены не были).
Для построения нетрадиционной архитектуры возьмём в качестве образца структуру зрительной коры головного мозга, расположенную преимущественно в затылочных долях полушарий. Особенности архитектуры зрительной коры головного мозга:
-
Кортикальные столбы (колонки) - базовые объединения (~80‑120 нейронов), проходящие вертикально через все слои коры [2 (plos.org)]. Данные колонки образуют модули - функциональные блоки, содержащие полный набор нейронов для обработки всех возможных ориентаций линий и данных от обоих глаз в конкретной точке поля зрения [3 (nature.com)].
-
Связи между колонками реализованы по Small‑World топологии [4 (arxiv.org)]. Эта топология в виде графа обеспечивает высокую эффективность при низком энергопотреблении мозга [5 (frontiersin.org)].
-
Внутри колонки информация передаётся через возбуждающие и тормозящие пути, организованные нейронами [6 (nature.com)]. Баланс возбуждения‑торможения (E‑I Balance) является фундаментом обработки информации и помехоустойчивой нейронной селективности.
-
Пластичность Хебба - правило, согласно которому одновременно активированные нейроны усиливают свои синаптические связи [7 (biorxiv.org)]. Такая синаптическая пластичность лежит в основе обучения и накоплении опыта [8 (arxiv.org)], который как известно - сын ошибок трудных.
-
Взаимодействие между нейронами происходит не только линейно, но и рекуррентно [9 (sciencedirect.com)], позволяя информации проходить по вертикальным колонкам как сверху‑вниз, так и снизу‑вверх [10 (nih.gov)].
Попробуем реализовать эту биологическую архитектуру на базе искусственных нейронных сетей с сохранением их главного преимущества - быстрого обучения за счет градиентов и батчей. Пойдем о простого к сложному: создадим файл под названием brain.py и импортируем необходимые пакеты:
#!/usr/bin/env python3
import torch
from torch import nn
import torch.nn.functional as F
import networkx as nx
import math
Теперь создадим класс кортикального столба для моделирования колонок нейронов в коре мозга с балансом возбуждения и торможения.
Параметры:
fc_exc- линейный слой для возбуждающих нейронов. Инициализируем с помощью Kaiming Normal и будем активировать положительные сигналы через ReLU активациюfc_inh- линейный слой для тормозящих нейронов Инициализация с помощью Xavier Uniformи будем активировать с помощью Sigmoid активацииe_i_ratio- коэффициент баланса в виде соотношения возбуждающих и тормозящих нейроновdropout- коэффициент указывающий сколько данных отбрасывать dropout слою для предотвращения переобучения
Учтем то что, в реальной коре примерно 80 процентов нейронов являются возбуждающими пирамидальными, а около 20 процентов тормозными нейронами. Тормозные нейроны регулируют общую активность сети и предотвращают её чрезмерное возбуждение. Кроме того, мы будем использовать нормализацию и проекционный слой, который помогает справляться с ситуациями, когда размерности входа и выхода не совпадают.
class Column(nn.Module):
def __init__(self, in_feat: int, out_feat: int, e_i_ratio: float = 0.8, dropout: float = 0.1):
super().__init__()
self.fc_exc = nn.Linear(in_feat, out_feat, bias=False)
self.fc_inh = nn.Linear(in_feat, out_feat, bias=False)
self.norm = nn.LayerNorm(out_feat)
self.dropout = nn.Dropout(dropout)
self.e_i_ratio = e_i_ratio
nn.init.kaiming_normal_(self.fc_exc.weight, nonlinearity='relu')
nn.init.xavier_uniform_(self.fc_inh.weight)
self.use_projection = (in_feat != out_feat)
if self.use_projection:
self.projection = nn.Linear(in_feat, out_feat, bias=False)
def forward(self, x):
exc = F.relu(self.fc_exc(x))
inh = torch.sigmoid(self.fc_inh(x))
out = exc * (1.0 - self.e_i_ratio * inh)
if self.use_projection:
out = out + self.projection(x)
out = self.norm(out)
out = self.dropout(out)
return out
Это база наших вычислений. Вся кора головного мозга человека состоит примерно из 300млн подобных кортикальных колонок (упрощенно).
Связь между такими колонками происходит с помощью графа типа Small-World. Создадим матрицу смежности графа по Small-World модели Уоттса-Строгатца (Watts-Strogatz) с помощью пакета networkx:
Параметры:
num_nodes- количество связываемых колонокk- количество ближайших соседей в кольце с которыми будет связана колонкаp- вероятность перезаписывания связи
Строим регулярное кольцо, каждая колонка соединена с k/2 соседями слева и справа. С вероятностью p каждая связь заменяется на случайную (с дальним узлом). Такой подход обеспечит частые локальные связи между соседними областями и редкие дальние связи между удаленными регионами.
def make_small_world(num_nodes: int, k: int = 4, p: float = 0.1) -> torch.Tensor:
G = nx.watts_strogatz_graph(num_nodes, k, p)
adj = torch.zeros(num_nodes, num_nodes, dtype=torch.float32)
for i, j in G.edges():
adj[i, j] = 1.0
adj[j, i] = 1.0
return adj
Это наша топология связей между кортикальными колонками внутри нейронной сети.
Обрабатывать получаемые сигналы из графа будем с помощью механизма вычисляющего веса важности сообщений от соседних колонок. Таким образом каждая колонка будет сама решать, какие соседи наиболее релевантны для её текущего состояния и усиливать их сигналы.
class AttentionGate(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.query = nn.Linear(dim, dim, bias=False)
self.key = nn.Linear(dim, dim, bias=False)
self.scale = math.sqrt(dim)
def forward(self, center: torch.Tensor, neighbors: torch.Tensor, adj_mask: torch.Tensor):
q = self.query(center).unsqueeze(1)
k = self.key(neighbors)
scores = torch.bmm(q, k.transpose(1, 2)) / self.scale
scores = scores.squeeze(1)
scores = scores.masked_fill(adj_mask.unsqueeze(0) == 0, -1e9)
weights = F.softmax(scores, dim=-1)
return weights
Это наш механизм внимания.
Теперь у нас есть все компоненты для чтобы построить мезокортикальную нейронную сеть.
Создадим массив кортикальных колонок, связанных с помощью Small-World графа и будем обучать его веса связей (adj_weight) с помощью правила Хебба, а веса нейронов внутри колонок будем обучать с помощью классического метода градиентного спуска. Каждая колонка будет слушать своих соседей, а механизм внимания определять, от кого брать информацию. Контроль активности (decay_factor) будет следить за тем чтобы сигналы не затухали и не «взрывали» сеть.
class BrainNetwork(nn.Module):
def __init__(self,
num_columns: int = 64,
in_dim: int = 784,
col_out: int = 128,
top_out: int = 10,
graph_k: int = 8,
graph_p: float = 0.15,
message_iters: int = 4,
plasticity_lr: float = 5e-5,
use_attention: bool = True,
e_i_ratio: float = 0.8,
dropout: float = 0.1):
super().__init__()
self.num_columns = num_columns
self.message_iters = message_iters
self.plasticity_lr = plasticity_lr
self.use_attention = use_attention
self.columns = nn.ModuleList([Column(in_dim, col_out, e_i_ratio=e_i_ratio, dropout=dropout) for _ in range(num_columns)])
if use_attention:
self.attention_gates = nn.ModuleList([AttentionGate(col_out) for _ in range(num_columns)])
adj_struct = make_small_world(num_columns, k=graph_k, p=graph_p)
self.register_buffer('adj_struct', adj_struct)
self.adj_weight = nn.Parameter(torch.randn(num_columns, num_columns) * 0.1)
self.register_buffer('activity_avg', torch.ones(num_columns))
self.homeostatic_rate = 0.01
self.intermediate = nn.Sequential(
nn.Linear(col_out, col_out),
nn.ReLU(),
nn.Dropout(dropout),
nn.LayerNorm(col_out)
)
self.top_fc = nn.Linear(col_out, top_out)
def _homeostatic_scaling(self, activations: torch.Tensor):
current_activity = activations.mean(dim=(0, 2))
with torch.no_grad():
self.activity_avg = (1 - self.homeostatic_rate) * self.activity_avg + self.homeostatic_rate * current_activity
scale = 1.0 / (self.activity_avg.unsqueeze(0).unsqueeze(2) + 1e-6)
return activations * scale.detach()
def _column_activations(self, x):
pre = torch.stack([col(x) for col in self.columns], dim=1)
w = torch.sigmoid(self.adj_weight)
adj = self.adj_struct * w
post = pre.clone()
decay_factor = 0.9
for iter_idx in range(self.message_iters):
if self.use_attention:
new_post = []
for col_idx in range(self.num_columns):
center = post[:, col_idx, :]
adj_mask = adj[col_idx]
attn_weights = self.attention_gates[col_idx](
center, post, adj_mask
)
neigh_msg = torch.einsum('bc,bcd->bd', attn_weights, post)
new_col = F.relu(post[:, col_idx, :] + 0.2 * neigh_msg)
new_post.append(new_col)
post = torch.stack(new_post, dim=1)
else:
neigh_msg = torch.einsum('ij,bjd->bid', adj, post)
post = F.relu(post + 0.2 * neigh_msg)
post = decay_factor * post + (1 - decay_factor) * pre
post = self._homeostatic_scaling(post)
return pre, post
def _hebb_update(self, pre_acts: torch.Tensor, post_acts: torch.Tensor):
pre = F.normalize(pre_acts.mean(dim=(0, 2)), dim=0)
post = F.normalize(post_acts.mean(dim=(0, 2)), dim=0)
delta_corr = torch.ger(pre, post)
delta_anti = -0.1 * torch.ger(post, post)
delta = delta_corr + delta_anti
delta = delta * self.adj_struct
with torch.no_grad():
self.adj_weight += self.plasticity_lr * delta
self.adj_weight.data = torch.tanh(self.adj_weight.data)
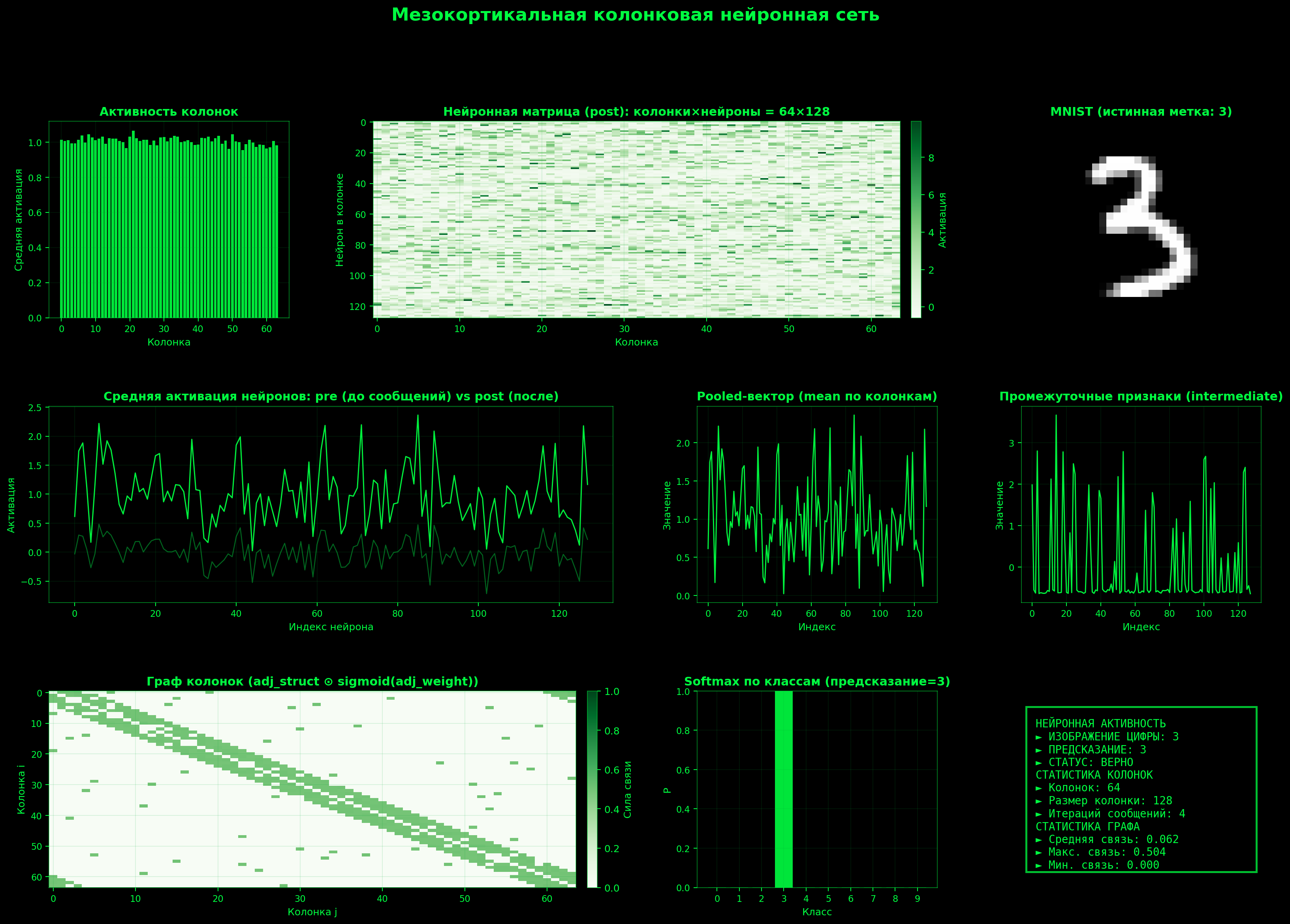
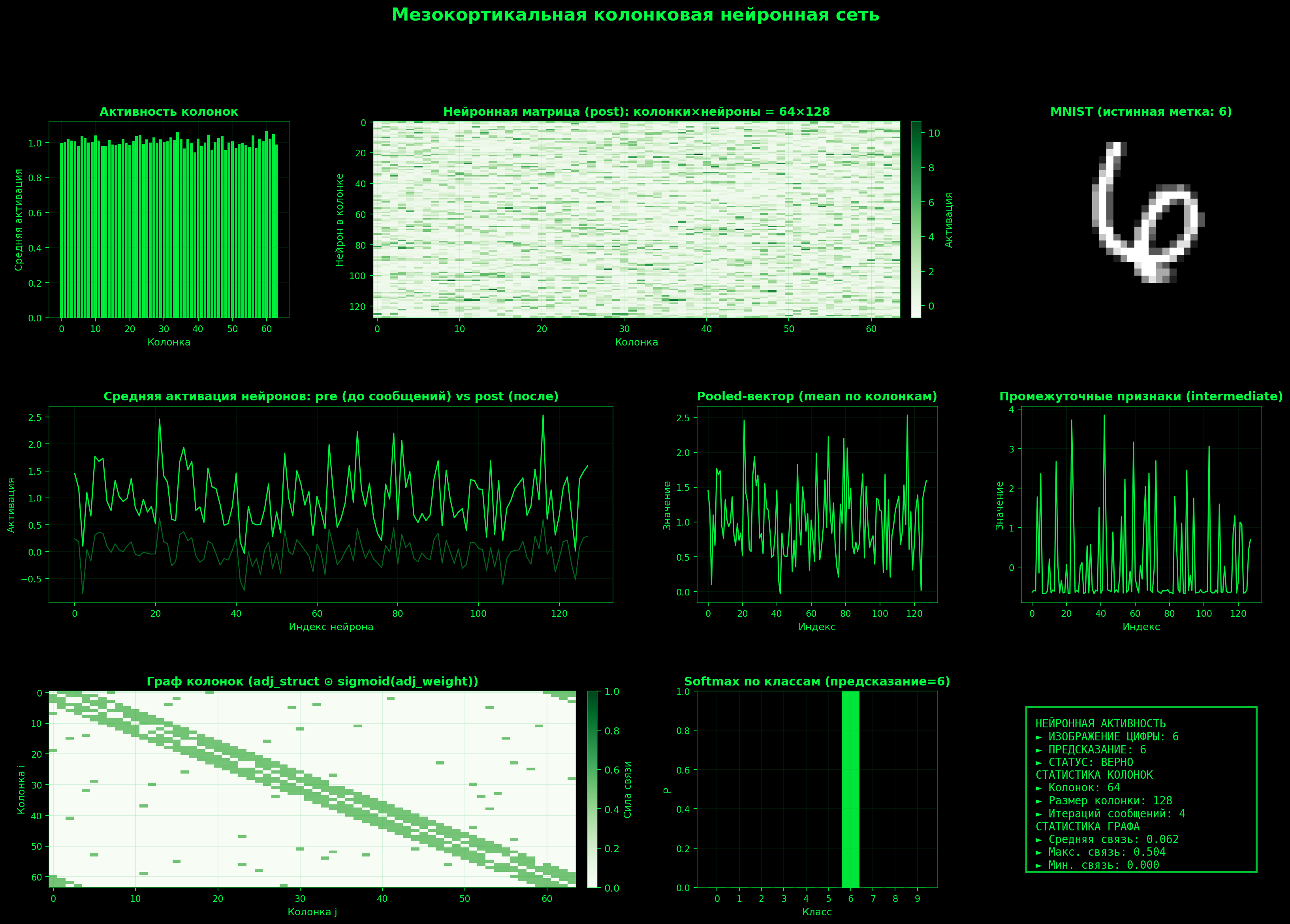
def forward(self, x):
_, post = self._column_activations(x)
pooled = torch.mean(post, dim=1)
features = self.intermediate(pooled)
logits = self.top_fc(features)
return logits
def training_step(self, batch):
x, y = batch
pre, post = self._column_activations(x)
pooled = torch.mean(post, dim=1)
features = self.intermediate(pooled)
logits = self.top_fc(features)
loss = F.cross_entropy(logits, y)
loss.backward()
self._hebb_update(pre.detach(), post.detach())
return loss
Мы получили нетрадиционную нейронную сеть всего за полторы сотни строк кода не самого хорошего качества. В ней не только используются аналоги биологических элементов мозга, но и само обучение работает в двух режимах параллельно:
- Unsupervised (Hebbian): адаптирует структуру графа связей. Так обучаются элементы биологического мозга.
- Supervised (Backprop): оптимизирует веса колонок и классификатора. Так обучаются искусственные нейронные сети.
Пришло время проверить получившуюся сеть на практике. Создадим второй файл под названием train.py
В нем не будет ничего интересного потому обойдемся комментариями прямо в коде:
#!/usr/bin/env python3
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from brain import BrainNetwork
batch_size = 128 # размер батча, для расчетов на CPU уменьшите до 16-32
epochs = 10 # количство эпох
learning_rate = 1e-3 # шаг обучения
weight_decay = 1e-5 # L2-регуляризация весов
# гипермпараметры модели
hyperparams = {
"num_columns": 64, # количество кортикальных колонок
"in_dim": 784,
"col_out": 128,
"top_out": 10,
"graph_k": 8,
"graph_p": 0.15,
"message_iters": 4,
"plasticity_lr": 5e-5
}
# загружаем датасет, при первом запуск еон автоматически скачается
transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x: x.view(-1))])
train_set = datasets.MNIST(root='.', train=True, download=True, transform=transform)
test_set = datasets.MNIST(root='.', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set , batch_size=batch_size, shuffle=False)
# создаем модель
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = BrainNetwork(**hyperparams).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=len(train_loader)*12)
# начинаем обучение
for epoch in range(1, epochs+1):
model.train()
for batch_idx, (x, y) in enumerate(train_loader, start=1):
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
loss = model.training_step((x, y))
optimizer.step()
scheduler.step()
# периодически выводим статистику
if batch_idx % 100 == 0:
model.eval()
correct = total = 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
logits = model(x)
preds = logits.argmax(dim=1)
correct += (preds == y).sum().item()
total += y.size(0)
acc = correct / total
print(f'Epoch {epoch:02d} [{batch_idx}/{len(train_loader)}] Loss={loss.item():.4f} Test Accuracy={acc*100:.2f}%')
# сохраняем результат
state = {
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"loss": loss.item(),
"hyperparams": hyperparams
}
torch.save(state, "brain.pth")
Запустим 64 кортикальные колонки на 10 эпохах обучения: python train.py
Каждые 100 шагов будут выводиться данные о текущем уровне обучения:
Epoch 01 [100/469] Loss=0.2053 Test Accuracy=92.43%
Epoch 01 [200/469] Loss=0.1944 Test Accuracy=95.60%
Epoch 01 [300/469] Loss=0.0724 Test Accuracy=95.94%
Epoch 01 [400/469] Loss=0.1135 Test Accuracy=95.75%
Epoch 02 [100/469] Loss=0.0689 Test Accuracy=97.23%
Epoch 02 [200/469] Loss=0.0824 Test Accuracy=97.19%
Epoch 02 [300/469] Loss=0.0323 Test Accuracy=97.47%
Epoch 02 [400/469] Loss=0.0722 Test Accuracy=97.45%
Epoch 03 [100/469] Loss=0.0831 Test Accuracy=96.70%
Epoch 03 [200/469] Loss=0.0265 Test Accuracy=97.62%
Epoch 03 [300/469] Loss=0.0633 Test Accuracy=97.89%
Epoch 03 [400/469] Loss=0.0287 Test Accuracy=98.07%
Epoch 04 [100/469] Loss=0.0363 Test Accuracy=97.98%
Epoch 04 [200/469] Loss=0.0259 Test Accuracy=97.99%
Epoch 04 [300/469] Loss=0.0197 Test Accuracy=97.74%
Epoch 04 [400/469] Loss=0.0046 Test Accuracy=97.90%
Epoch 05 [100/469] Loss=0.0247 Test Accuracy=98.14%
Epoch 05 [200/469] Loss=0.0222 Test Accuracy=98.08%
Epoch 05 [300/469] Loss=0.0089 Test Accuracy=98.15%
Epoch 05 [400/469] Loss=0.0594 Test Accuracy=98.04%
Epoch 06 [100/469] Loss=0.0078 Test Accuracy=98.19%
Epoch 06 [200/469] Loss=0.0132 Test Accuracy=98.06%
Epoch 06 [300/469] Loss=0.0037 Test Accuracy=98.27%
Epoch 06 [400/469] Loss=0.0076 Test Accuracy=98.33%
Epoch 07 [100/469] Loss=0.0061 Test Accuracy=98.55%
Epoch 07 [200/469] Loss=0.0014 Test Accuracy=98.52%
Epoch 07 [300/469] Loss=0.0015 Test Accuracy=98.48%
Epoch 07 [400/469] Loss=0.0014 Test Accuracy=98.47%
Epoch 08 [100/469] Loss=0.0024 Test Accuracy=98.55%
Epoch 08 [200/469] Loss=0.0003 Test Accuracy=98.49%
Epoch 08 [300/469] Loss=0.0002 Test Accuracy=98.51%
Epoch 08 [400/469] Loss=0.0081 Test Accuracy=98.52%
Epoch 09 [100/469] Loss=0.0009 Test Accuracy=98.58%
Epoch 09 [200/469] Loss=0.0005 Test Accuracy=98.60%
Epoch 09 [300/469] Loss=0.0004 Test Accuracy=98.61%
Epoch 09 [400/469] Loss=0.0004 Test Accuracy=98.66%
Epoch 10 [100/469] Loss=0.0003 Test Accuracy=98.71%
Epoch 10 [200/469] Loss=0.0002 Test Accuracy=98.73%
Epoch 10 [300/469] Loss=0.0003 Test Accuracy=98.72%
Epoch 10 [400/469] Loss=0.0002 Test Accuracy=98.73%
Обучение на видеокарте потребовало примерно 3Gb видеопамяти и заняло 30 минут. Результат: 98.73% точности на тестовых образцах. Отличный результат на уровне современных традиционных моделей. Желающие могут самостоятельно поэкспериментировать с количеством кортикальных колон и эпох обучения для достижения точности 99+%
В данной работе была реализована и экспериментально исследована нетрадиционная нейросетевая архитектура, основанная на принципах организации коры головного мозга млекопитающих. Разработанный подход показывает, что ключевые принципы организации биологического мозга, такие как модульная архитектура, динамическая структурная пластичность и баланс между локальной и глобальной связностью, могут эффективно использоваться в современном машинном обучении.
Модель продемонстрировала точность 98.73% на тестовой выборке MNIST после 10 эпох обучения, что сопоставимо с результатами лучших классических глубоких сверточных сетей на том же количестве эпох, при этом используя принципиально иную парадигму обучения.
В процессе обучения менялись не только параметры отдельных модулей (колонок), но и структура самой сети, то есть связи между модулями. Колонки, которые активировались одновременно при обработке похожих данных, автоматически укрепляли связи друг с другом и образовывали специализированные группы. Это похоже на то, как устроен биологический мозг: там нейроны тоже объединяются в группы для выполнения конкретных задач.
Текущая реализация с 64 колонками может быть расширена до сотен или тысяч модулей для решения более сложных задач, при этом структура малого мира обеспечит субквадратичный рост числа связей, что критично для вычислительной эффективности.
Несмотря на отличные результаты эта модель лишь основа, база для понимания и перехода к более «биологичным» искусственным нейронным сетям класса «Больной Ублюдок», у которых вообще отсутствуют привычные механизмы машинного обучения, такие как градиенты, обратное распространения ошибки и батчинг. Но об этом в следующий раз.
References
- Isong et al., Building Efficient Lightweight CNN Models, arXiv (2025)
- G. Moreni et al., Cell-type-specific firing patterns in a V1 cortical column model, PLoS Computational Biology (2025)
- P. Goltstein et al., A column-like organization for ocular dominance in mouse visual cortex, Nature (2025)
- M. Ghader at al., Backpropagation-free Spiking Neural Networks with the Forward-Forward Algorithm, arXiv (2025)
- Y. A. Sugimoto et al., Network structure influences self-organized criticality in small-world brain networks, Frontiers in Systems Neuroscience (2025)
- J. Kilgore et al., Biologically-informed excitatory and inhibitory ratio for robust spiking neural network training, Nature (2025)
- I. Ahokainen et al., A unified model of short- and long-term plasticity, bioRxiv (2025)
- N. Ravichandran et al., Unsupervised representation learning with Hebbian synaptic and structural plasticity in brain-like networks (2025)
- R. Zhang et al., Dynamic grouping of ongoing activity in V1 hypercolumns, NeuroImage (2025)
- J. Trajkovic et al., Top-down and bottom-up interactions rely on nested brain oscillations to shape rhythmic visual attention sampling, Pubmed (2025)



