18 июня, после более месяца разработки, состоялся выпуск 0.12.0 библиотеки и кроссплатформенной консольной утилиты ZXC (github.com), реализующих высокопроизводительное многопоточное асимметричное сжатие без потерь и оптимизированное для игровых ресурсов, прошивок и пакетов приложений. Формат разработан по принципу «один раз записать, многократно читать» (WORM).
В отличие от таких кодеков, как LZ4, ZXC жертвует скоростью сжатия ради максимальной пропускной способности при распаковке.
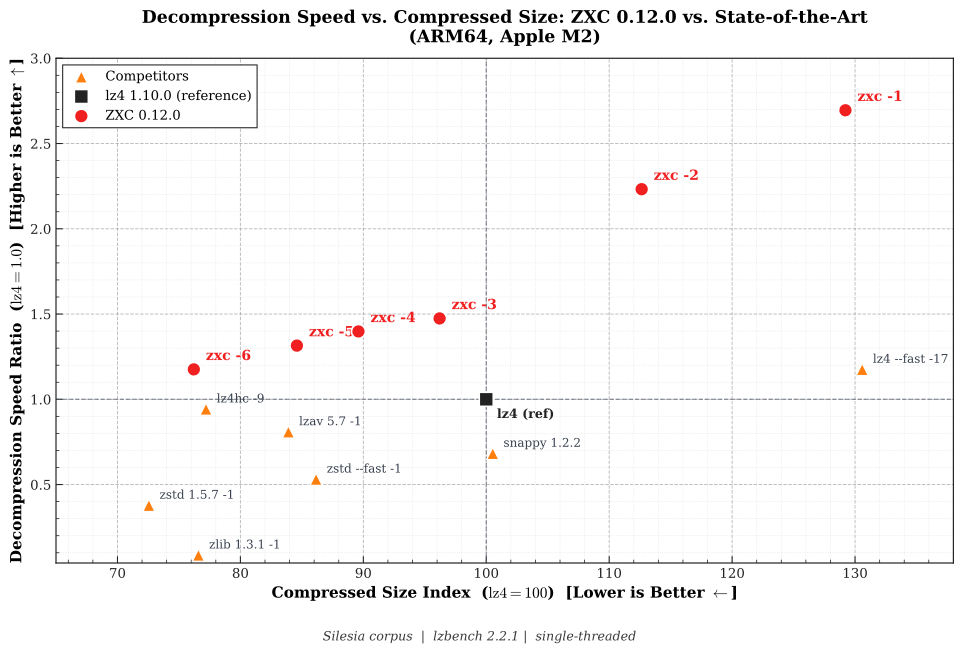
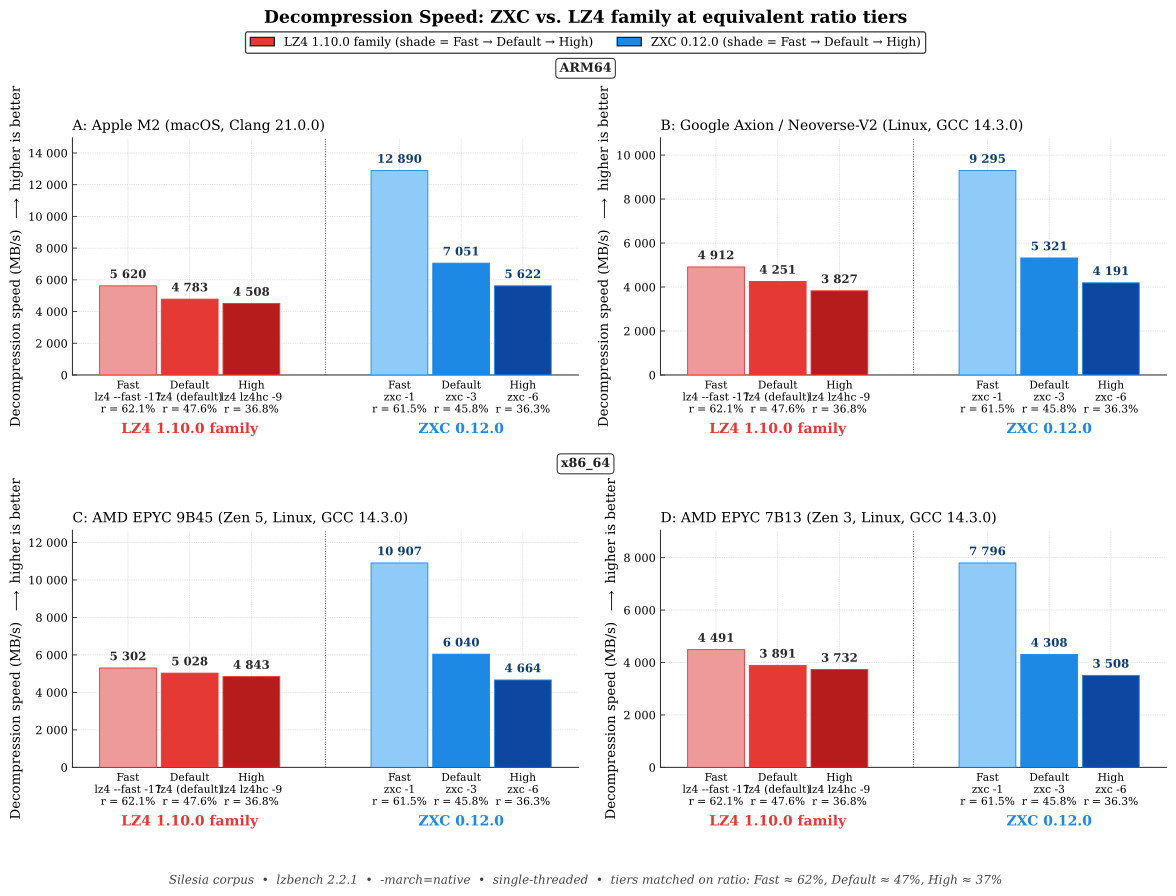
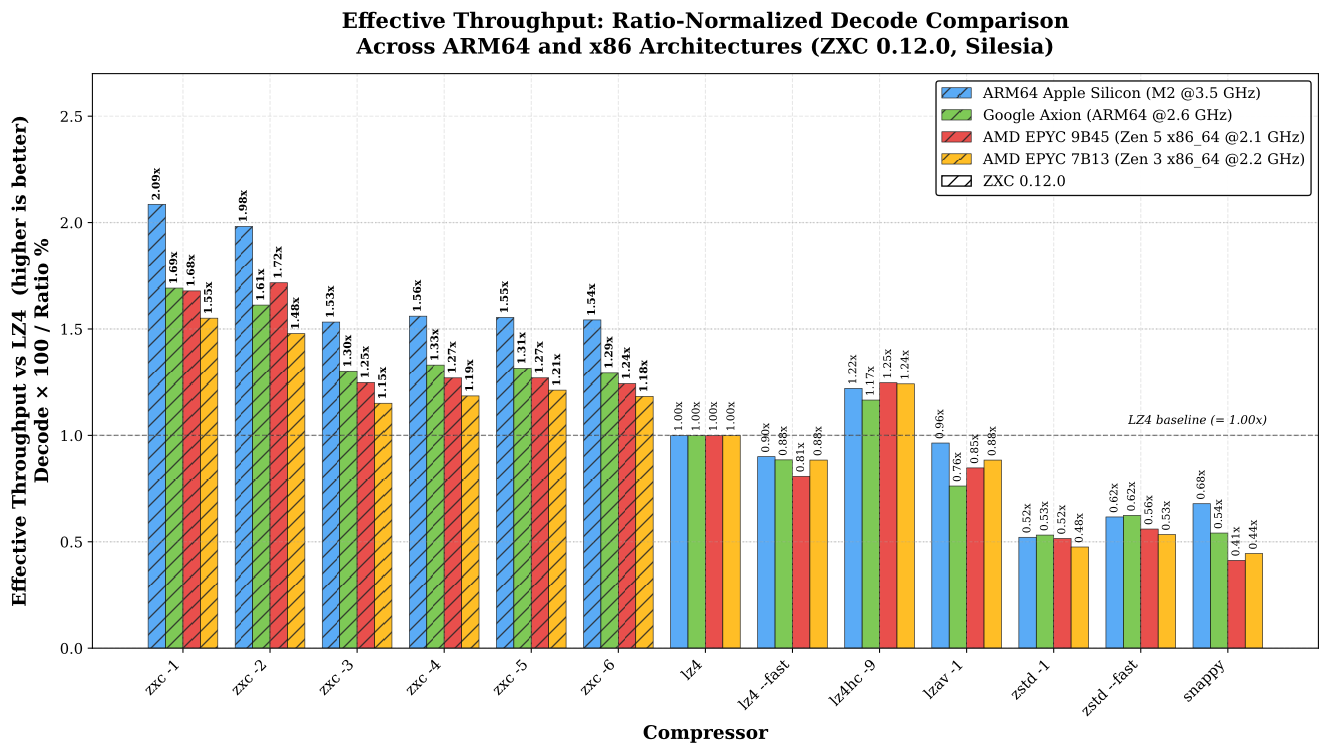
Декларируется скорость распаковки на 10-47% выше, чем у LZ4 с уровнем компрессии по умолчанию, с равным или более высоким коэффициентом сжатия.
Главное изменение этого выпуска – возможность сжатия с использованием предварительно обученного словаря на основе репрезентативных образцов, что значительно уменьшает размер архивов с небольшими блоками или большим количеством маленьких файлов.
Версия формата контейнера обновлена до v6, а версия библиотеки SOVERSION увеличена с 3 до 4.
Проект написан на языке C и распространяется по лицензии BSD 3.
Основные изменения:
- компрессия с предварительно обученным словарём и общей таблицей Хаффмана;
- изменения в консольной утилите:
- добавлен параметр
--trainдля обучения словаря на основе входных файлов (путь к выходным файлам указывается с помощью параметра-o; по умолчанию —dictionary_<dict_id>.zxd). Этот параметр заменил прежний параметр--train-dict PATH; -D, --dict FILE— сжимает или распаковывает файл, используя словарьFILE;-l, --list— выводит содержание архива или информацию о словаре.zxd;- добавлен новый псевдоним для распаковки
unzxc— он инсталлируется в виде символьной ссылки наzxcи по умолчанию работает в режиме распаковки (эквивалентно командеzxc -d).
- добавлен параметр
- компрессия с уровнем 6 примерно на 10% быстрее версии 0.11.0;
- декомпрессия с уровнями 1 и 2 примерно на 3% быстрее версии 0.11.0;
- другие улучшения и исправления ошибок.




