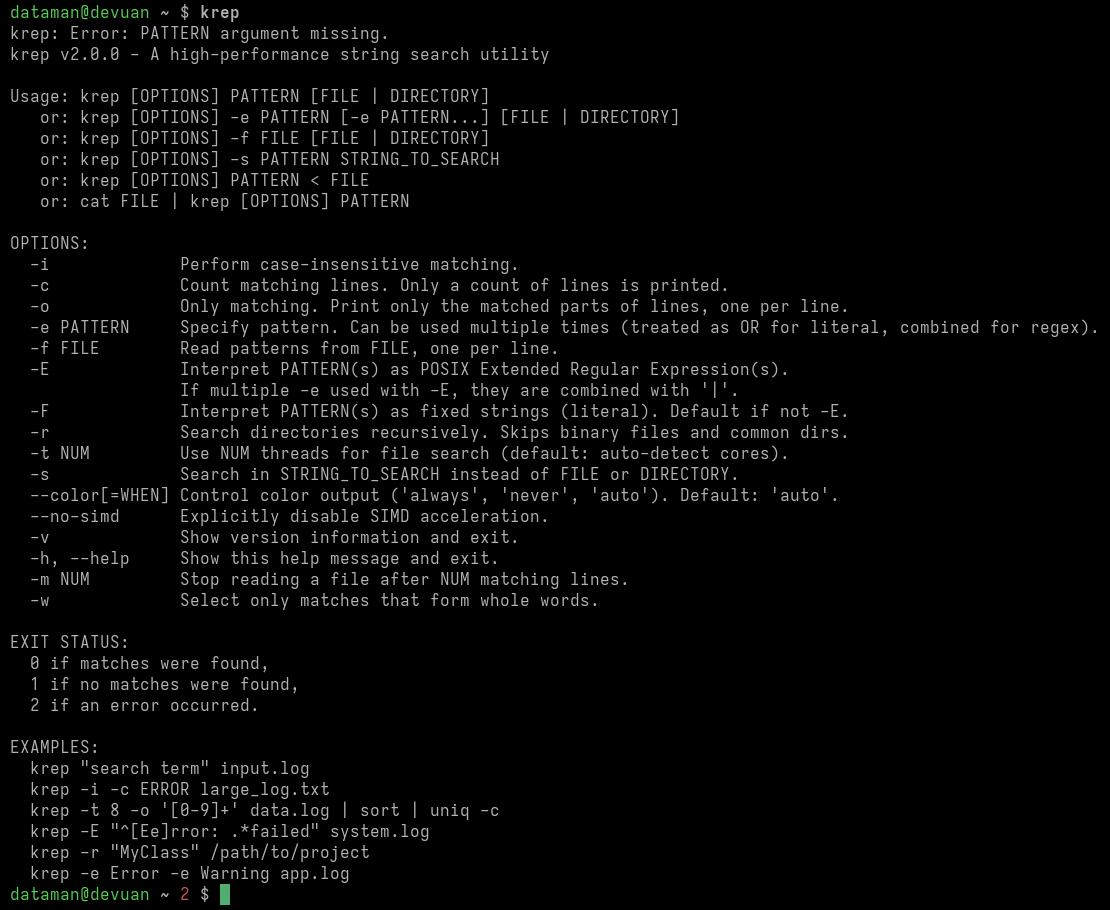
11 февраля состоялся выпуск 2.0.0 krep — высокопроизводительной, многопоточной, SIMD-оптимизированной консольной утилиты для поиска строк.
Основные особенности:
- В зависимости от типа шаблонов для оптимальной производительности используются алгоритмы Бойера—Мура—Хорспула, Кнута—Морриса—Пратта или Ахо—Корасик.
- Использование отображаемого на память файла при обработке больших файлов.
- Автоматическое распределение поиска по доступным ядрам процессора.
- SIMD-оптимизация с поддержкой SSE4.2, AVX2 и NEON.
Утилита написана на языке C и распространяется по лицензии BSD-2.
Изменения:
- значительно улучшена производительность многопоточной обработки пути в функции
search_file; - добавлен скрипт
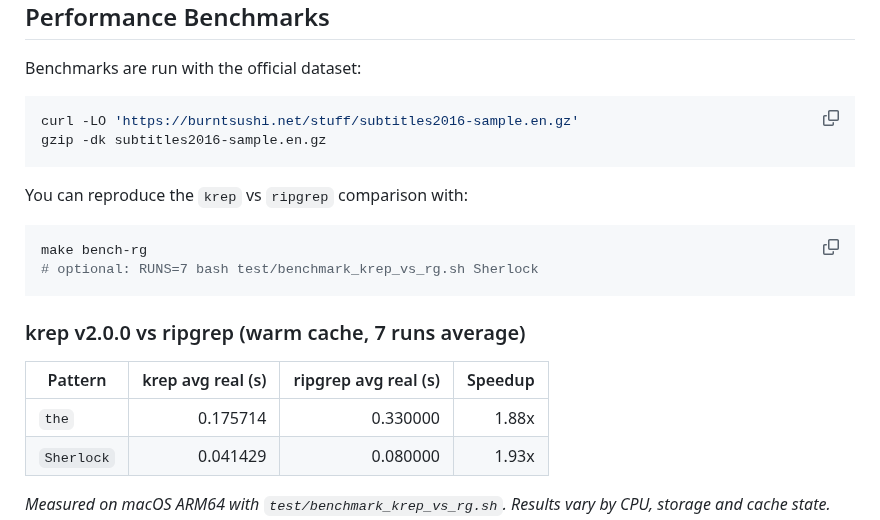
test/benchmark_krep_vs_rg.shдля сравненияkrepиripgrep; - исправлена ошибка рекурсивного пропуска минимизированных ресурсов (вида
.min.*); - улучшено тестирование.