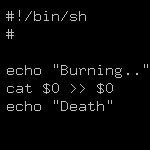
Привет. Есть небольшой скрипт вывода диапазона из целых чисел
Begin=101 End=105
for i in $(seq $Begin $End); do echo $i
Хочу написать тоже самое только вывод следующих диапазонов но с точками:
101.1-101.99 101.5-110.100 101.1.1-102.2.99
Желательно через цикл т.к. каждое число $i будет далее выдаваться на поиск в find строку.
привидите примеры пожалуйста.