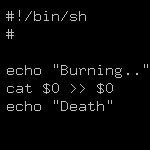
День добрый!
Ребят помогите пож. добиться удаления текста между тэгами <description>техт бла бла</description>: http://gross-trading.com/feed.xml
Попытался сам таким макаром, но без результата:
sed 's#\(<description>\).*\(</description>\)#\1'xxxxx'\2#g' test.xml > test2.xml
sed '/<description>/,/<\/description>/{//!d}' test.xml > test2.xml