Есть у меня некоторый классификатор, который выдаёт результаты в абстрактных попугаях. Мне нужно из них получить вероятность, подогнав эти попугаи функцией P(x). Посоветуйте хорошую функцию, ибо логистическая кривая мне подходит не весьма.
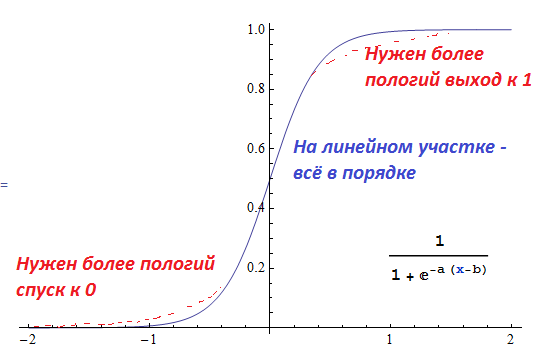
Собственно, P(X): непрерывна и монотонно возрастает P(-inf) --> 0 P(inf) --> 1 P(x-b) - 0.5 нечётная, где b - некий задаваемый параметр
Раньше я пользовался логистической кривой, однако практика показывает, что если она нормально подгоняет мои данные на линейном участке, то таки слишком быстро выходит к 0 или 1.
Выглядит это так: http://i48.fastpic.ru/big/2012/1125/9c/8257ae703912c1c0c658e2991fb5f89c.png
Арктангенс - наоборот, спадает немного слишком медленно. Нет ли чего ещё?
Перемещено post-factum из general





{kind=link}