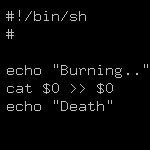
Есть абстрактная файлопомойка, с кучей файлов о накопленном багаже знаний: что-то в текстовом виде, или с примитивной разметкой а-ля markdown, конфиги, логи, примеры; что-то в pdf или doc/odt. Не разберешь уже, в общем. Думаю, у многих есть такая. Так вот вопрос о том как организовать во всем это безобразии полноценный поиск. Т.е. чтобы можно было _сразу_ искать:
- в имени файла (find)
- в содержимом (grep)
- в pdf (pdfgrep)
Юниксвей это круто, но хотелось бы больше практичности. Что посоветуете?