Zabbix 3.2
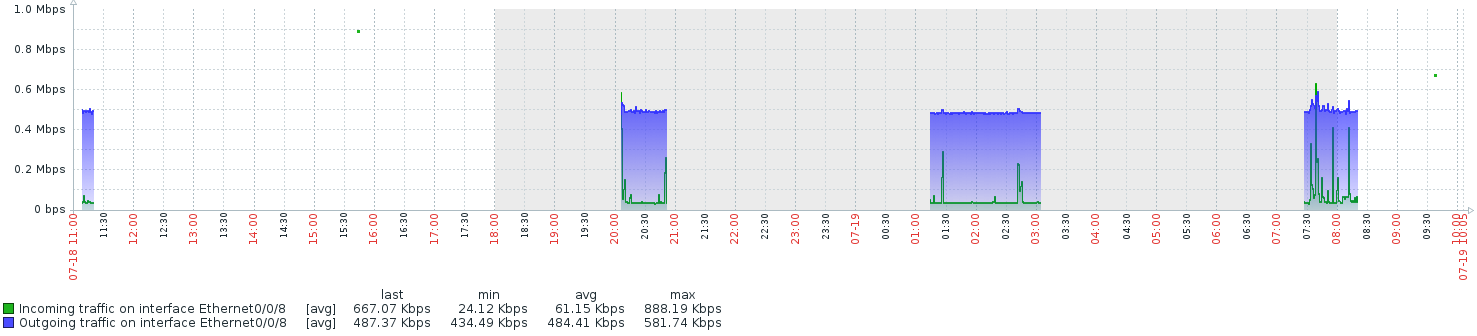
Наблюдаю такую картину: https://habrastorage.org/webt/q9/th/ym/q9thymfb6bdajvy9ifwoejkzkie.png
Заббикс внезапно перестает заполнять график данными.
Через snmpget устройство отвечает всегда, т.е. проблема, скорее всего, на стороне мониторинга.
snmpget -v 2c -c xxx -On 10.47.177.161 IF-MIB::ifOutOctets.11
.1.3.6.1.2.1.2.2.1.16.11 = Counter32: 3337688614
snmpget -v 2c -c xxx -On 10.47.177.161 IF-MIB::ifOutOctets.11
.1.3.6.1.2.1.2.2.1.16.11 = Counter32: 3406793294По ICMP данные приходят непрерывно в тот же заббикс, т.е. проблема, скорее всего, в плоскости SNMP. При этом, по другим хостам, добавленным через те же шаблоны, проблем я не вижу - графики непрерывны.
Кто-нибудь сталкивался с таким поведением?



{kind=link}