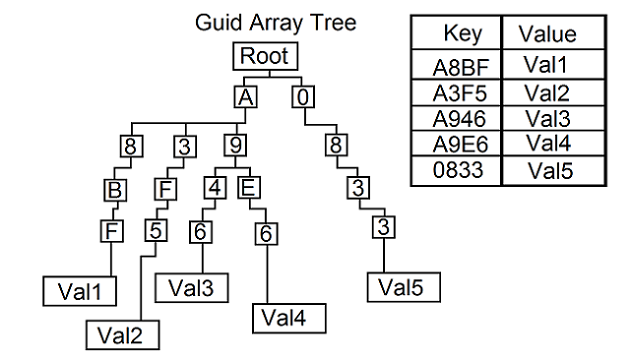
Дано
5 позиций, в каждой из них может стоять маленькая буква или число. Итого 36 ^ 5 вариантов. Занятые GUID храняться
Задача
Получить свободный GUID без коллизий с (желательно) равной вероятностью среди всех свободных GUID, обращаясь к хранилищу минимальное количество раз.
Как же правильно решать задачу такого типа? Хранить GUID в виде дерева и выбирать новый GUID согласно этому дереву? Есть ли готовые решения? (для линупса естественно)









{kind=link}